
Тест GeForce RTX 5080 в сравнение с RTX 4080, RTX 4090 и RX 7900 XTX: знакомство с NVIDIA Blackwell
02-06-2025
В этом обзоре протестируем новинку 50-й серии NVIDIA: расскажем, как она устроена внутри, ознакомимся с архитектурными особенностями и, конечно, погоняем в играх и сравним с несколькими быстрыми оппонентами.
Чтобы немного отдать уважения годам кропотливой работы инженеров, сначала проведем исследование внутреннего устройства линейки. И здесь следует уточнить, что вся дальнейшая информация будет относиться к полному чипу GB202, который даже в RTX 5090 не используется.
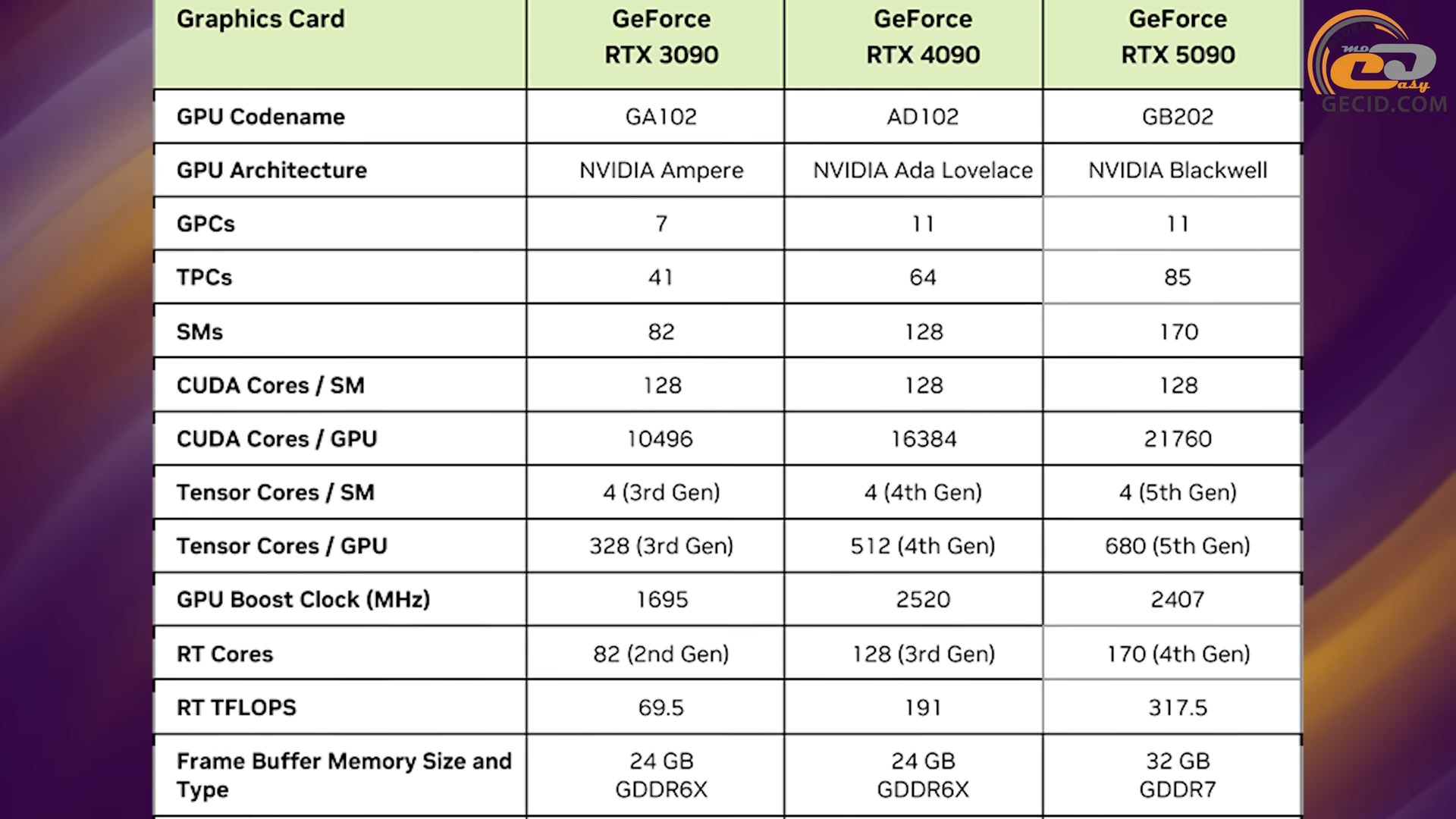
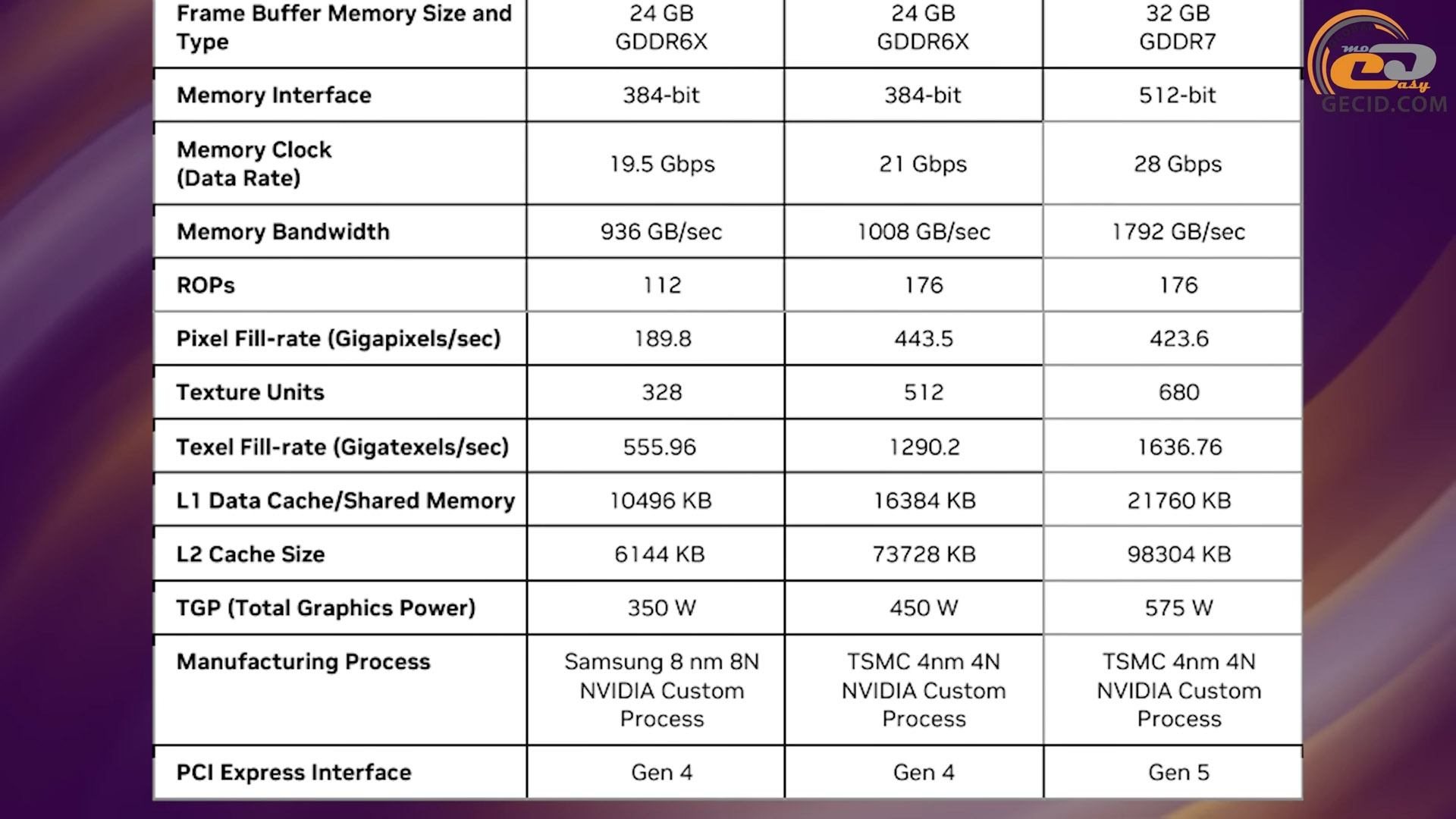
Изготовляется он по технологическому процессу TSMC 4NP, который на самом деле является усовершенствованными 5 нанометрами. Поэтому общее количество транзисторов между поколениями сильно замедлило свой темп роста - менее 21%. Для сравнения, переход от 8 нанометров 30-й серии к 5 нанометрам 40-й сопровождался наращиванием транзисторного бюджета более чем в 2,5 раза! Только эти цифры уже вызывают беспокойство, но не будем делать преждевременных выводов.
Исполнительный блок
Архитектура нового поколения получила название NVIDIA Blackwell в честь американского математика и по своей структуре является усовершенствованной версией GPU последних поколений.

На физическом уровне исполнительной части GPU увеличилось количество почти всех основных элементов. По сравнению с полным чипом Ada Lovelace 40-й линейки численность CUDA ядер выросла с 18432 до 24576, текстурных конвейеров и тензорных ядер – с 576 до 768, ядер для обработки трассировки лучей – со 144 до 192 (согласно количеству SM- А вот модулей растеризации осталось 192, как и в предыдущем поколении. Также следует отметить наличие 384 ядер для обработки 64-разрядных чисел с плавающей запятой, которые не указаны на диаграмме, но необходимы для совместимости с определенным программным обеспечением.
Основной доминирующей высокоуровневой аппаратной сущностью во всех графических процессорах семейства является 12 графических процессорных кластеров (сокращенно GPC), структуру которых Вы видите на экране. Каждый из них состоит из 8 кластеров для обработки текстур (TPC), 16 SM-блоков и 16 блоков ROP.
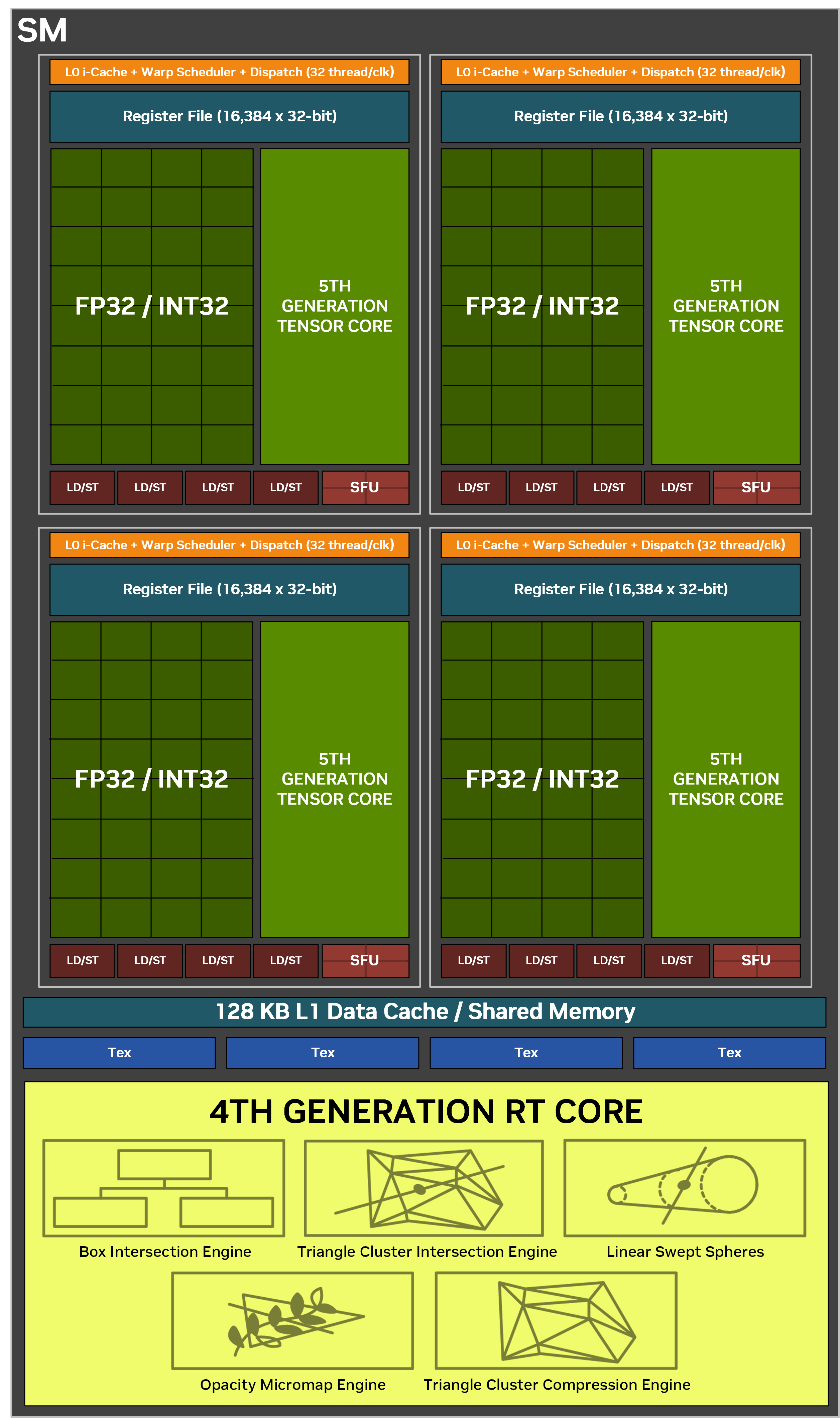
В свою очередь каждый SM-блок играет ключевую роль при параллельной обработке вычислений на разных по своему назначению ядрах – CUDA, тензорных и RT. Первых в его составе насчитывается 128 штук, вторых четыре и третьих по одному. Также здесь находится 256-килобайтный регистровый кэш и 128-килобайтный кэш первого уровня, который, как мы поняли, может автоматически делиться на меньшие по объему сегменты памяти в зависимости от типа нагрузки.
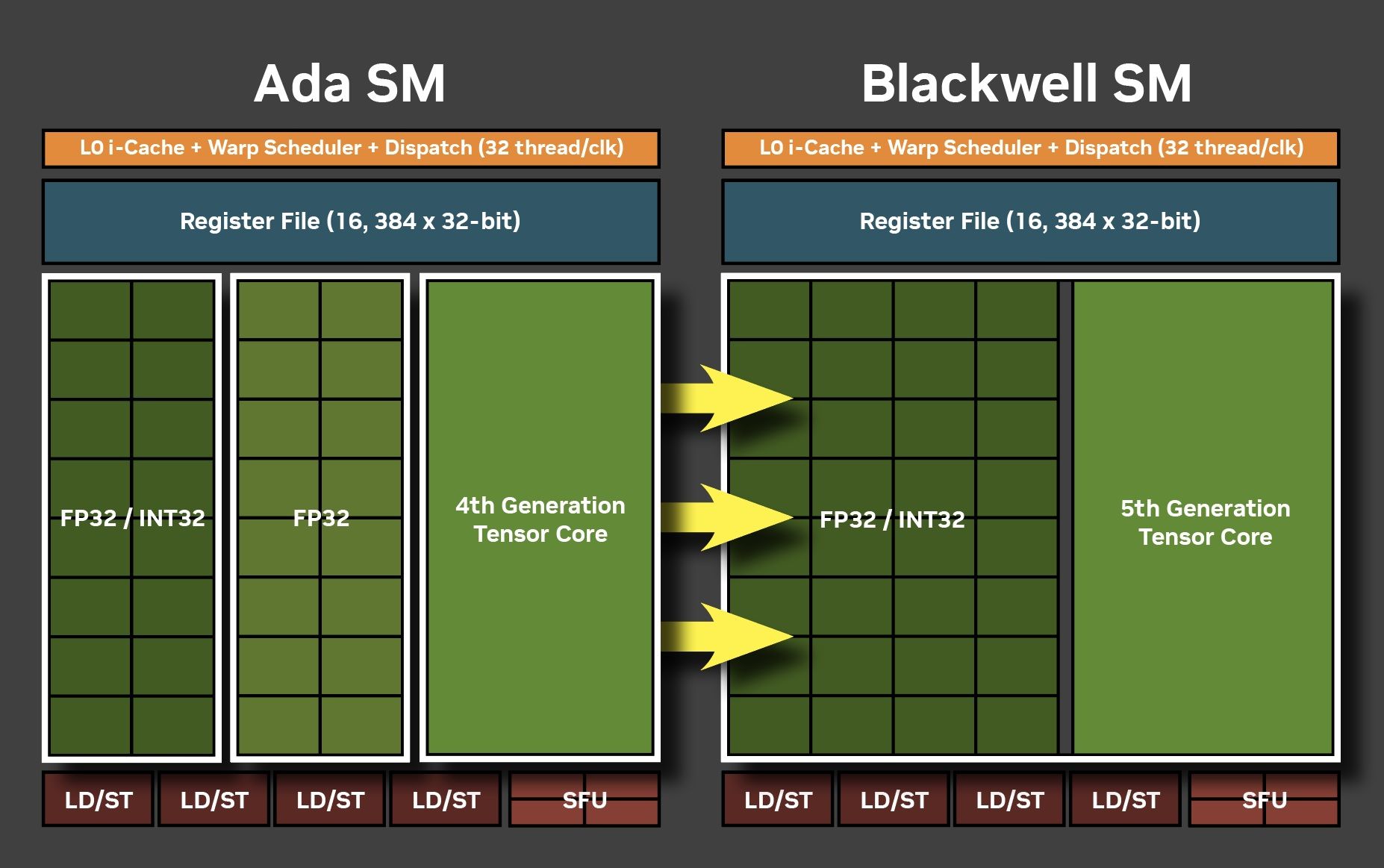
Существенно изменилась в новом поколении и логика работы с разными типами данных. По сравнению с Ada Lovelace, архитектура Blackwell удвоила обработку сделок над целыми числами. Но здесь есть хитрость – раньше половина SM-блоков в кластере GPC могла параллельно работать как с действительными, так и с целыми числами, а теперь на отдельно взятом такте GPU это могут быть исключительно числа либо первого, либо второго типа данных.
Последним усовершенствованием в исполнительной части чипа является кэш второго уровня. Он по сравнению с предыдущим поколением увеличился с 96 до 128 МБ.
VRAM
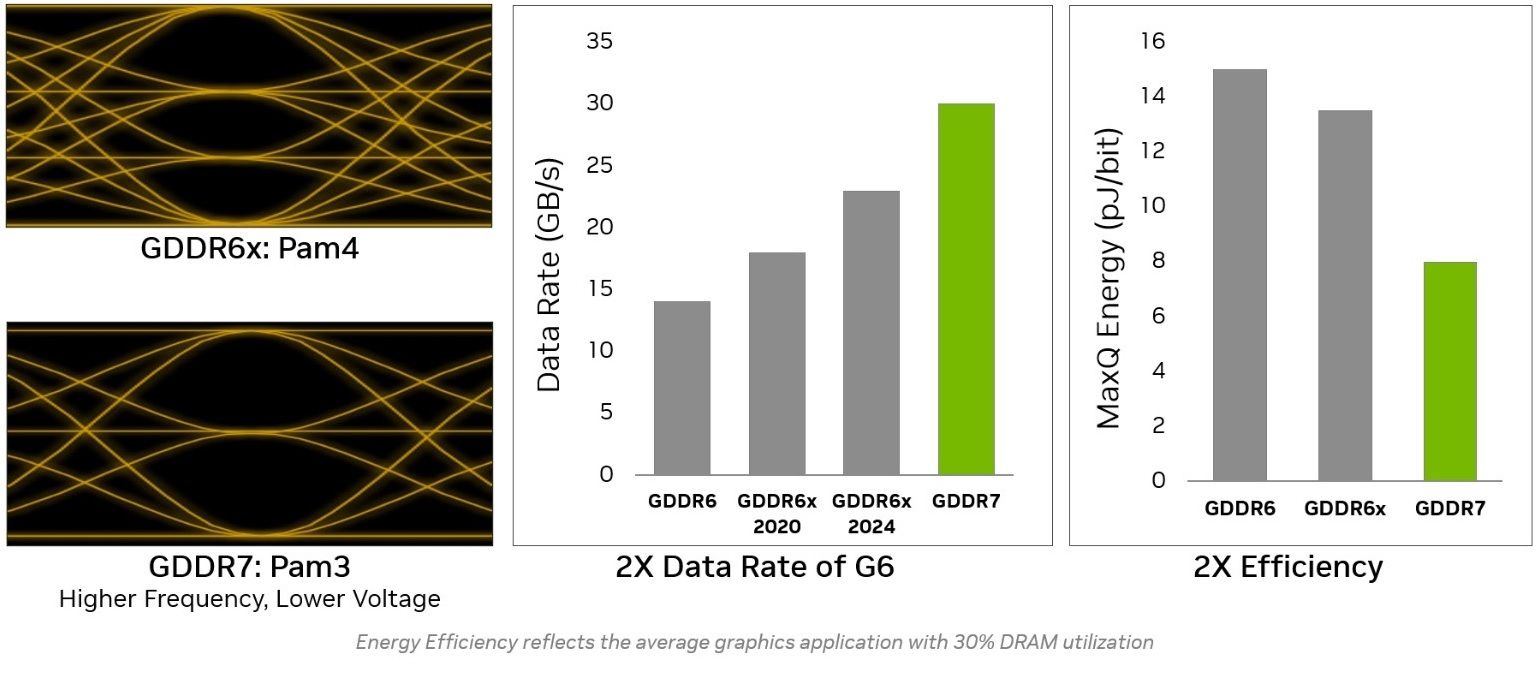
На втором месте по апгрейдам идет новый тип видеопамяти – GDDR7. По сравнению с самой быстрой VRAM прошлого поколения, GDDR6X существенно изменился сам способ передачи данных. Если предыдущее поколение использовало амплитудно-импульсную модуляцию с четырьмя уровнями сигнала (сокращенно PAM4), передавая два бита за один цикл обращения к видеобуферу, новое поколение может отличать три уровня сигнала (PAM3) и передавать при этом полтора бита за цикл. Сначала может показаться, что первый вариант быстрее второго, но не все так просто. Дело в том, что PAM4 плохо даются эффективные частоты выше 22,5 гигабит в секунду на контакт из-за высокой чувствительности к соотношению сигнал/шум. PAM3 в сочетании с инновационной схемой декодирования справляется с этой проблемой лучше, поэтому и частоты передачи данных ей доступны выше – сейчас до 30 гигабит в секунду. Еще добавляем к этому улучшенную работу с вводом/выводом и 512-битную шину, которую мы уже давно не видели в картах NVIDIA, и получаем почти 1,8 терабайта в секунду общей пропускной способности против 1-го терабайта в секунду в предыдущем поколении. Также соответствующие графики намекают, что такой подход еще и энергоэффективность улучшил почти вдвое по сравнению с обычной GDDR6 и на несколько десятков процентов в сравнении с ее «Иксовой» модификацией.
Тензорные ядра
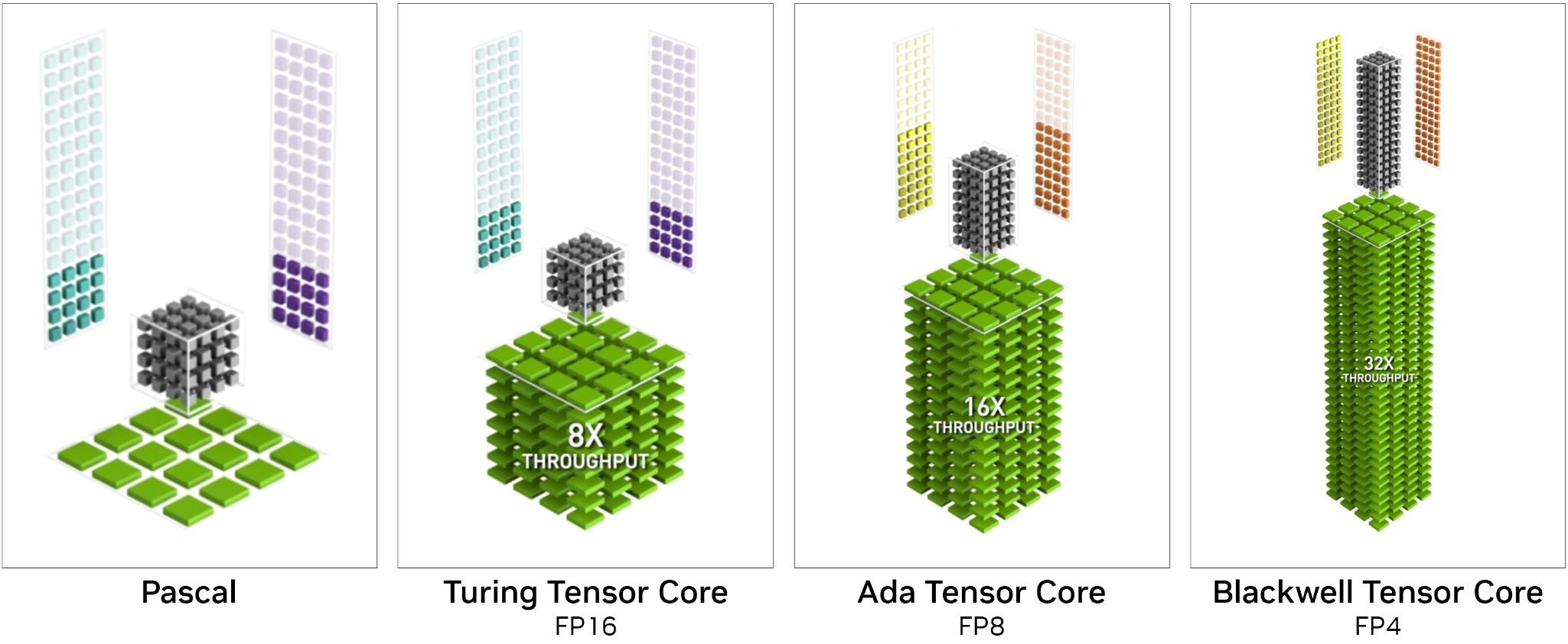
Обновились у Blackwell и тензорные ядра, основным предназначением которых являются операции над матрицами. Особенно часто они используются в алгоритмах машинного обучения и таких технологиях, как масштабирование изображения с помощью искусственного интеллекта и генерация кадров. Эволюционировали они в пятое поколение и впервые получили поддержку операций с низкой точностью над 4-х и 6-разрядными числами с плавающей запятой. Сделано это для экономии VRAM генеративными AI-моделями, которые за время существования существенно увеличили свои возможности, но и места потребовали больше. А чем меньше битность представления чисел, тем меньше памяти нужно для их хранения. В качестве примера специалисты NVIDIA провели эксперименты с моделью FLUX.dev от Black Forest Labs, которая может генерировать изображение по текстовому описанию, и заявляют о более чем двухкратной экономии видеобуфера при использовании 4-битного формата чисел по сравнению с 16-битным. При этом важна и скорость обработки – с FP16 процесс генерации проекта происходил втрое дольше.
RT-ядра
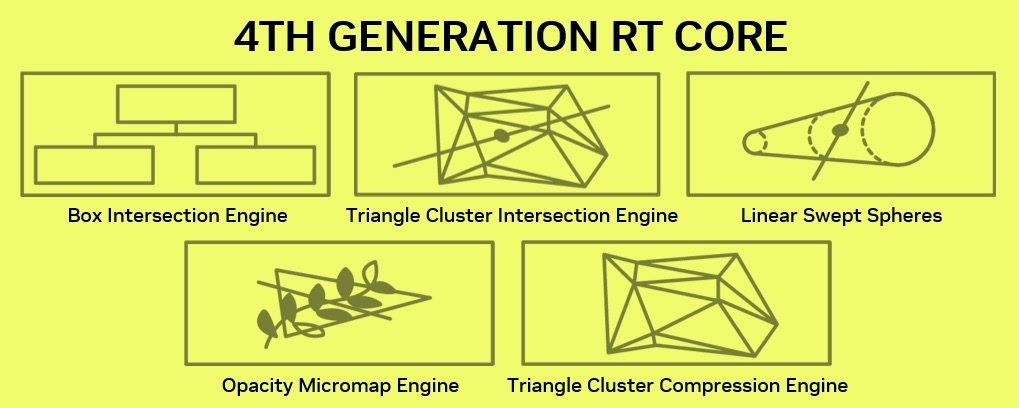
Усовершенствования получили и RT-ядра, которые обновились до четвертого поколения. Основной из них является удвоенная скорость обработки пересечений лучами полигонов за такт. Данная операция является одной из самых ресурсоемких в процессе трассировки, поэтому следует ожидать значительного прироста производительности нового GPU по данному направлению.
Но не только с помощью сырой производительности компания NVIDIA собирается бороться с неповоротливостью рейтрейсинга. Целый набор инновационных программных инструментов Mega Geometry должен помочь чипам NVIDIA вести соответствующие расчеты еще быстрее.

И здесь следует немного уточнить что такое структура-дерево BVH, потому что большинство усовершенствований касается именно ее.
Создана последняя для упрощения расчета столкновений 3D-объектов между собой или пересечения их лучами в реальном времени. Ведь проверка с высокой частотой коллизий сотен или даже тысяч примитивов, из которых состоят конечные объекты, превысит возможности любого современного ускорителя. А разбив каждый такой объект последовательно на все меньшие и меньшие части, появляется возможность существенно сэкономить вычислительные ресурсы. В случае лучей, GPU проверяет на пересечение наивысший по уровню элемент BVH и если оно есть, то спускается ниже по дереву и определяет с какими дочерними частями структуры лучи столкнулись, все остальные элементы (те с которыми контакта не возникло) отбрасываются и, соответственно, не просчитываются.
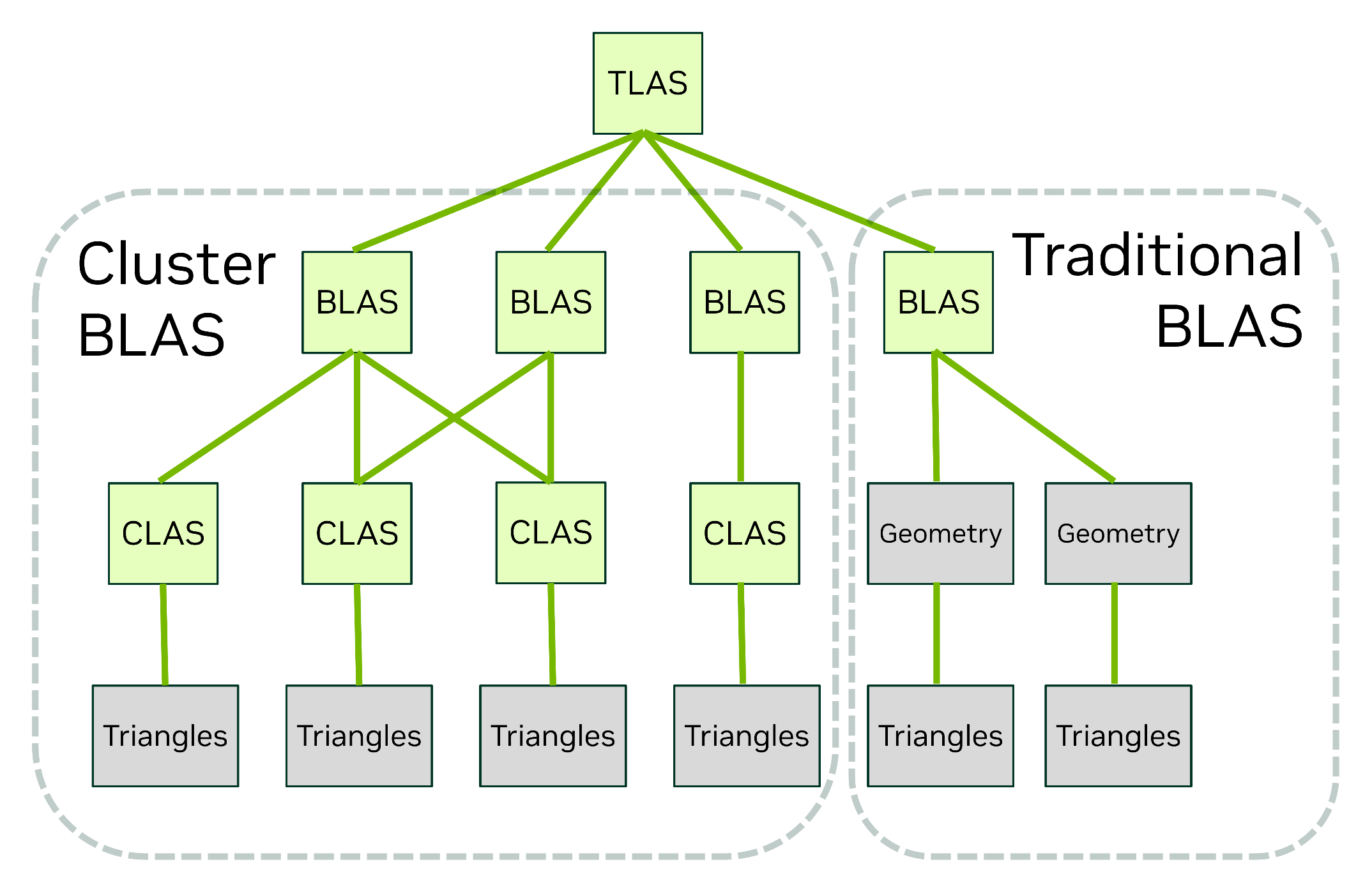
Так вот, во-первых, появился новый тип примитивов в дереве BVH во время RT-рендеринга – Cluster-level Acceleration Structures (сокращенно CLAS). Он на два порядка ускоряет построение структур, когда объекты, для которых они создаются, изменяют координаты расположения относительно точки обзора.
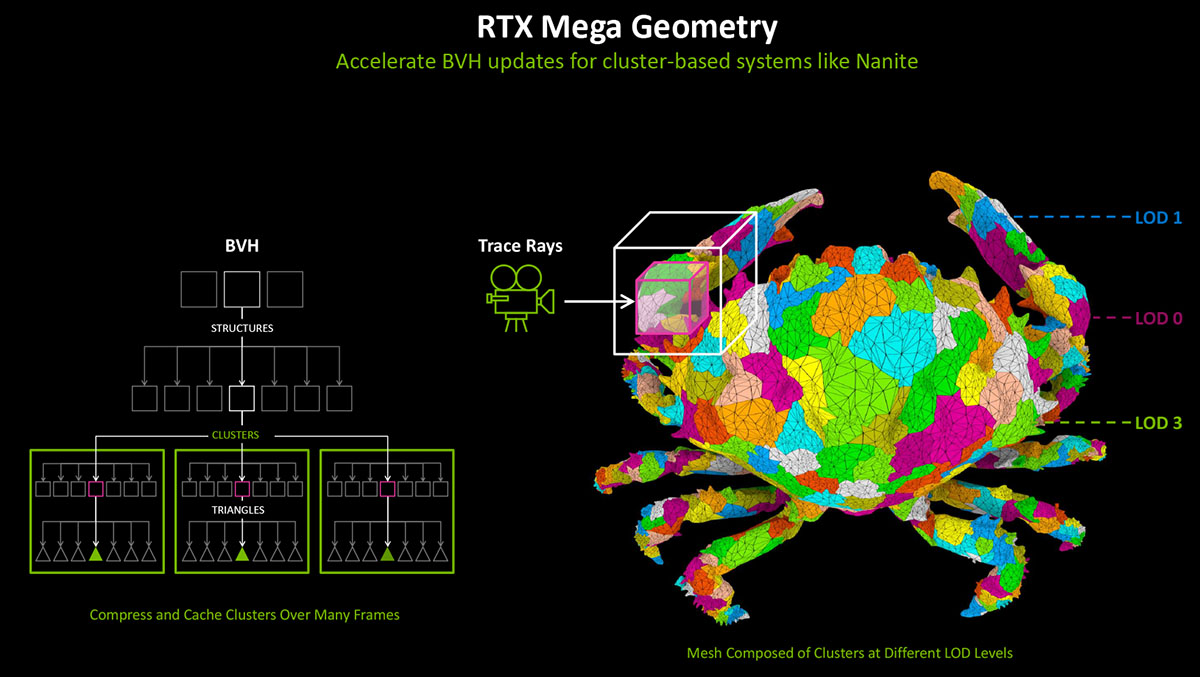
По сути это кэш из групп полигонов, который использует данные предыдущего кадра для оптимизации следующих. Особую пользу от такого подхода должна получить система виртуальной геометрии Nanite в Unreal Engine 5.

Во-вторых, изменился принцип построения статических структур высокого уровня в дереве BVH. Если раньше в каждом следующем кадре такие структуры создавались заново, то с переходом на Mega Geometry они разбиваются на части более низкого уровня один раз, а затем отделяются от аналогичных по рангу динамических структур и отправляются в отдельный кэш для использования в следующих кадрах.

И действительно, зачем в каждом кадре заново создавать, например стену дома, если движу известно, что в следующих кадрах она никуда не денется. Новый тип структуры получил название Partitioned Top-Level Acceleration Structure (PTLAS).
И здесь хорошая новость – технология Mega Geometry поддерживается на всех RTX ускорителях NVIDIA начиная с поколения Turing.
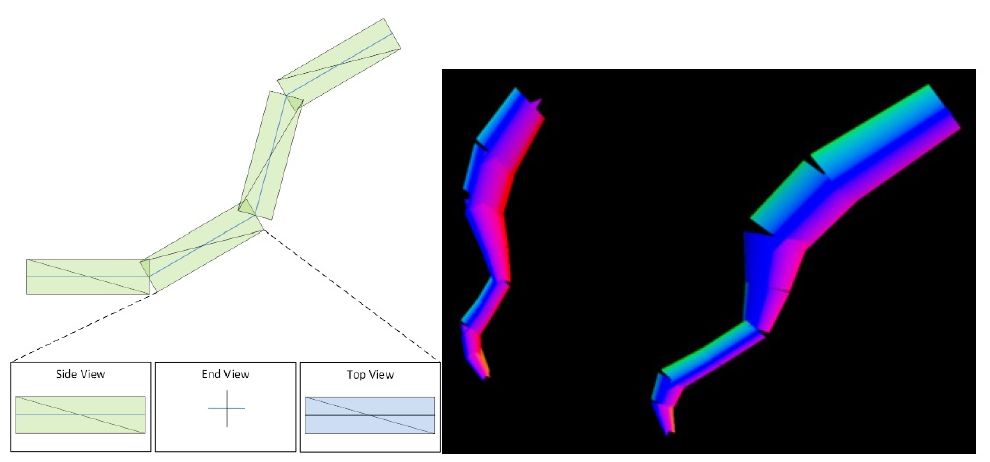
Идем дальше и коснемся темы, которую после выхода третьего Ведьмака, пожалуй, все уже и забыли – 3D-волосы, мех и аналогичные объекты. RT-ядра в поколении Blackwell на аппаратном уровне способны сотрудничать с новым видом примитивов – Linear Swept Spheres (сокращенно LSS), а также выполнять проверку пересечения их лучами. Основные изменения здесь кроются в способе представления меш-объектов.
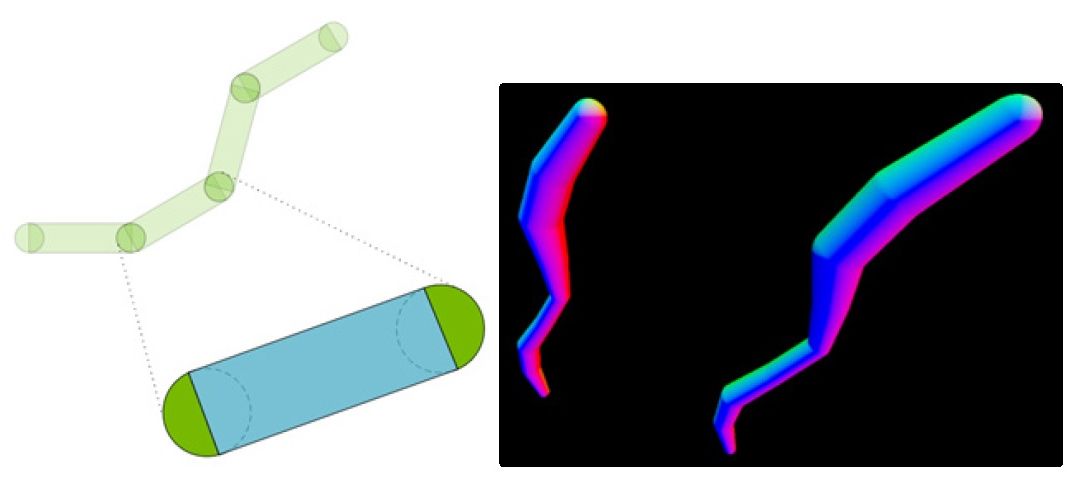
С LSS каждый волосок создается не с помощью полигонов и прямоугольных сегментов, как это было раньше, а с помощью сферы, которая «двигаясь» от начала до конца объекта и, изменяя диаметр, формирует цилиндрические сегменты.
Планировщики

Отвлечемся от лучей и обратим внимание на то, как GPU работает с разнородными вычислениями. Механизм Shader Execution Reordering обновился до версии 2.0 и получил несколько аппаратных и программных усовершенствований, которые должны вдвое улучшить функцию динамической сортировки потоков данных на различные типы ядер. Более подробной информации производитель не раскрывает, но известно, что с помощью специального API разработчики программного обеспечения смогут самостоятельно перенаправлять потоки данных на нужные вычислители для более оптимального их выполнения.
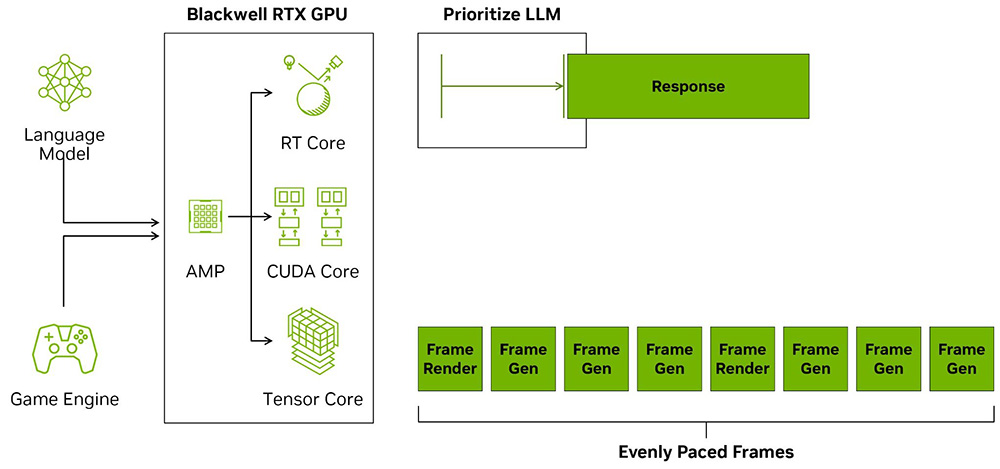
Также стоит упомянуть о еще одном обновленном планировщике – AI Management Processor (сокращенно AMP). Он аппаратно реализован с помощью специального процессора RISC-V, расположенного перед всеми вычислительными конвейерами GPU. Основной его задачей является менеджмент системных процессов, выполнение которых так или иначе связано с видеокартой. Такой подход существенно снижает нагрузку на центральный процессор, ведь раньше эту работу выполнял именно он. На программном уровне AMP взаимодействует с вшитой в Windows 10 и 11 технологией HAGS (Hardware-Accelerated GPU Scheduling).
Медиа движок
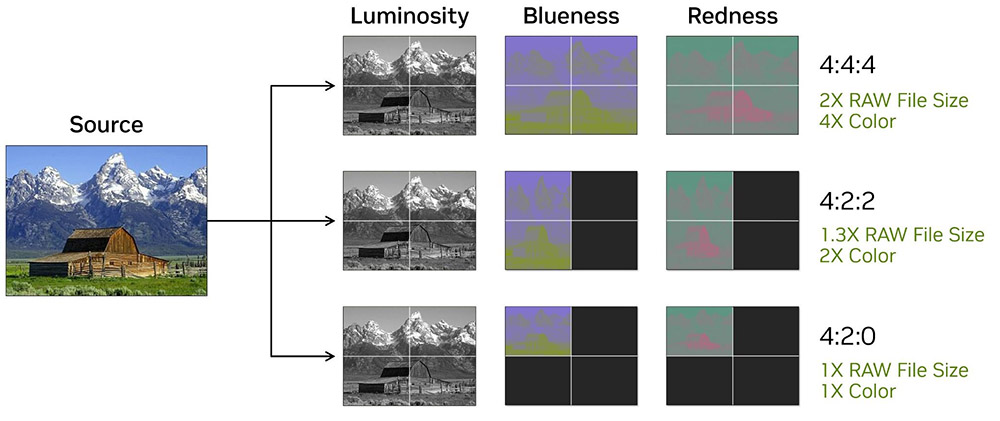
Еще из новенького в архитекутре Blackwell отметим появление аппаратной поддержки кодирования и декодирования видео в формате YUV 4:2:2 для видеокодеков H.264 и H.265, а также увеличение скорости декодирования H.264 вдвое и Ultra High Quality для AV1.

Вдобавок DisplayPort версии 2.1b должна увеличить пропускную способность видеопотока до 80 гигабит в секунду, что должно поднять планку разрешения и частоты до 8K при 165 Гц.
Энергоэффективность
Поскольку технологический процесс производства чипов 50-й линейки изменился не существенно, а количество транзисторов несколько выросло, большое внимание разработчикам пришлось уделить энергоэффективности. В частности, концепции Max-Q, которая получила несколько важных усовершенствований.

Первым из них является возможность отключения определенных частей чипа от тактового генератора, если они простаивают, не догружены или еще не успели изменить активный статус работы на пассивный. С этой же целью питание GPU-ядер и видеобуфер разделили на отдельные линии.
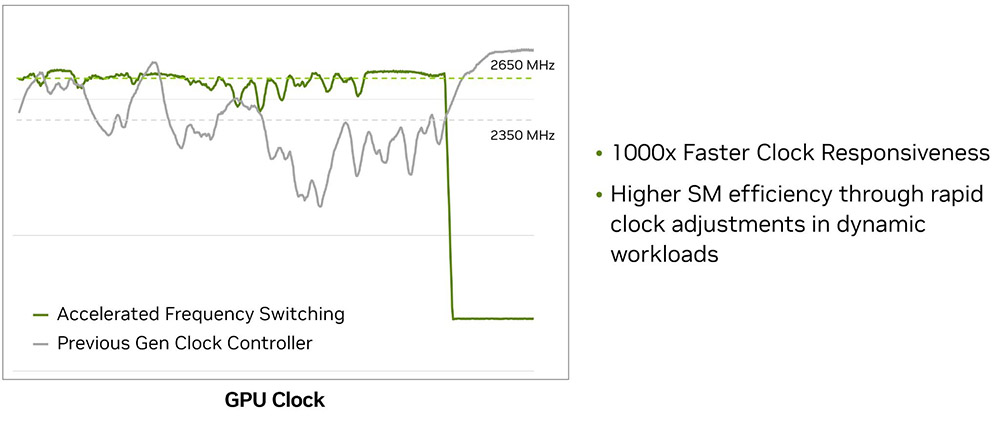
Второй инновацией является более быстрое переключение рабочей частоты чипа, которое в 1000 раз превышает показатели 40-й серии. Раньше частота динамически изменялась, но в конце концов подстраивалась под отдельный кадр. Теперь она может существенно варьироваться прямо во время его рендеринга.
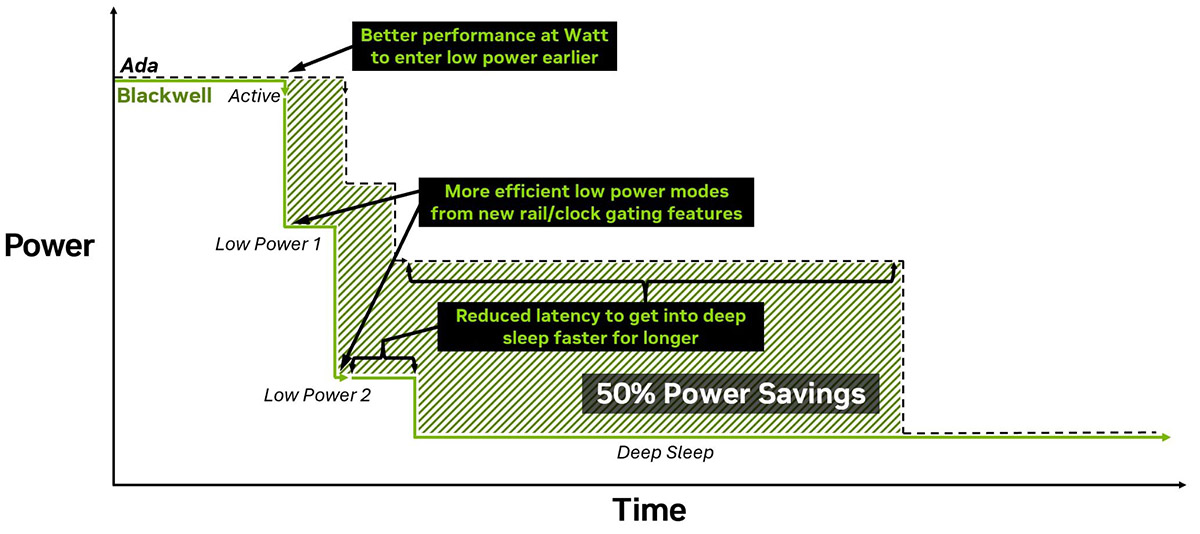
Напоследок, NVIDIA заявляет, что Blackwell переходит в режим гибернации в 10 раз быстрее, чем предыдущее поколение. Это позволяет сэкономить до 50% энергии в отдельных задачах, например при генерации текста небольшими языковыми моделями.
DLSS 4
Сразу предупредим, что технологию DLSS четвертого поколения, используемую 50-й линейкой, мы подробно рассмотрим в одном из следующих материалов. Здесь остановимся только на ее ключевых особенностях.
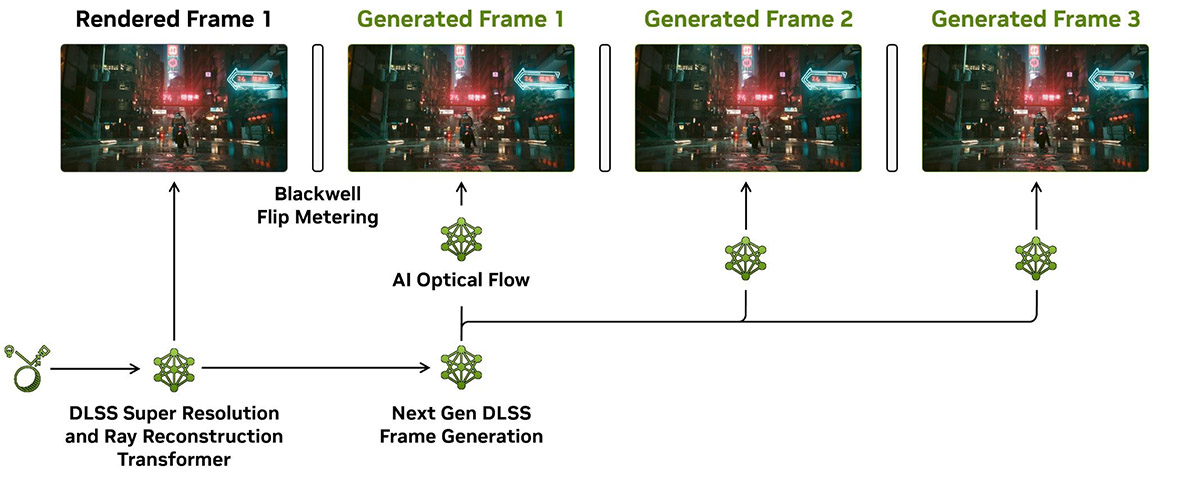
Уже не секрет, что с DLSS 4 карты NVIDIA могут генерировать не один, а сразу до трех дополнительных кадров на каждый честно визуализированный. Это стало возможным благодаря кардинально измененному подходу к работе технологии. Если раньше отслеживание потока смены кадров выполнялось на аппаратном уровне, то теперь за это отвечает отдельная нейросеть, которая и работает на 40% быстрее, и потребляет на 30% меньше VRAM.

Чтобы увеличенное количество сгенерированных кадров не привело к значительному input lag, обновление получила и хорошо знакомая технология Reflex, поднявшись до версии 2.0. Теперь перед выводом последнего сгенерированного кадра на дисплей сначала проверяются данные из устройств ввода. В соответствии с полученной информацией происходит коррекция, и только после этого кадр отправляется на экран.

Еще одним термином, к которому придется привыкать в новом поколении видеокарт, является модель Transformer. Простыми словами это новый подход к распознаванию и классификации первоначальных изображений с помощью нейросети для дальнейшего создания новых изображений. Такая обработка критически важна для DLSS Super Resolution, DLSS Ray Reconstruction и Deep Learning Anti-Aliasing (DLAA).
В предыдущем поколении применялась модель Convolutional Neural Network (CNN), которая анализировала изображения большими фрагментами. В то же время модель Transformer работает более точно – попиксельно, обеспечивая более высокое качество, детализацию и четкость ценой незначительной потери производительности.
Нейронные шейдеры
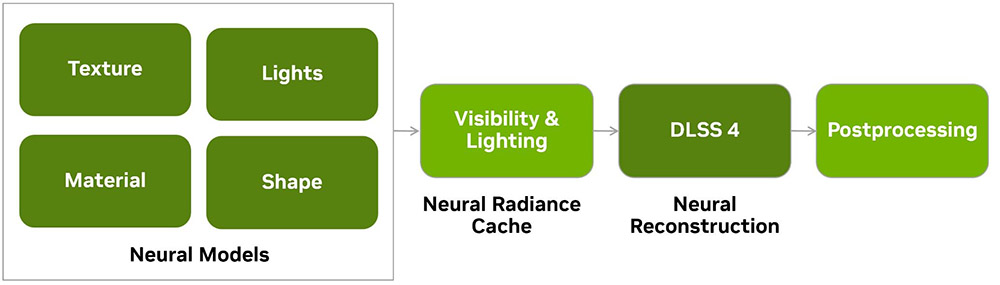
Последний, но не менее важный акцент от NVIDIA – нейронные шейдеры, которые, на наш взгляд, имеют не меньшее значение, чем мультифрейм-генерация.
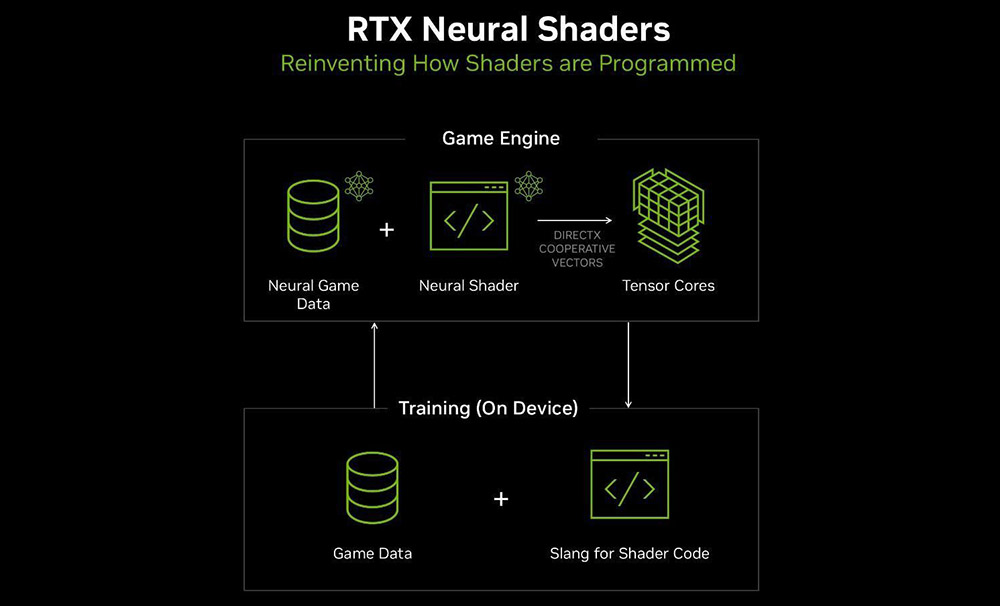
Компания сообщает, что в будущем традиционные шейдерные вычисления на CUDA-ядрах постепенно перейдут на тензорные и локальные нейросети. Уже сейчас линейка RTX 50 может предложить три направления, где этот подход обеспечит прирост производительности: RTX Neural Texture Compression, RTX Neural Materials и Neural Radiance Cache.
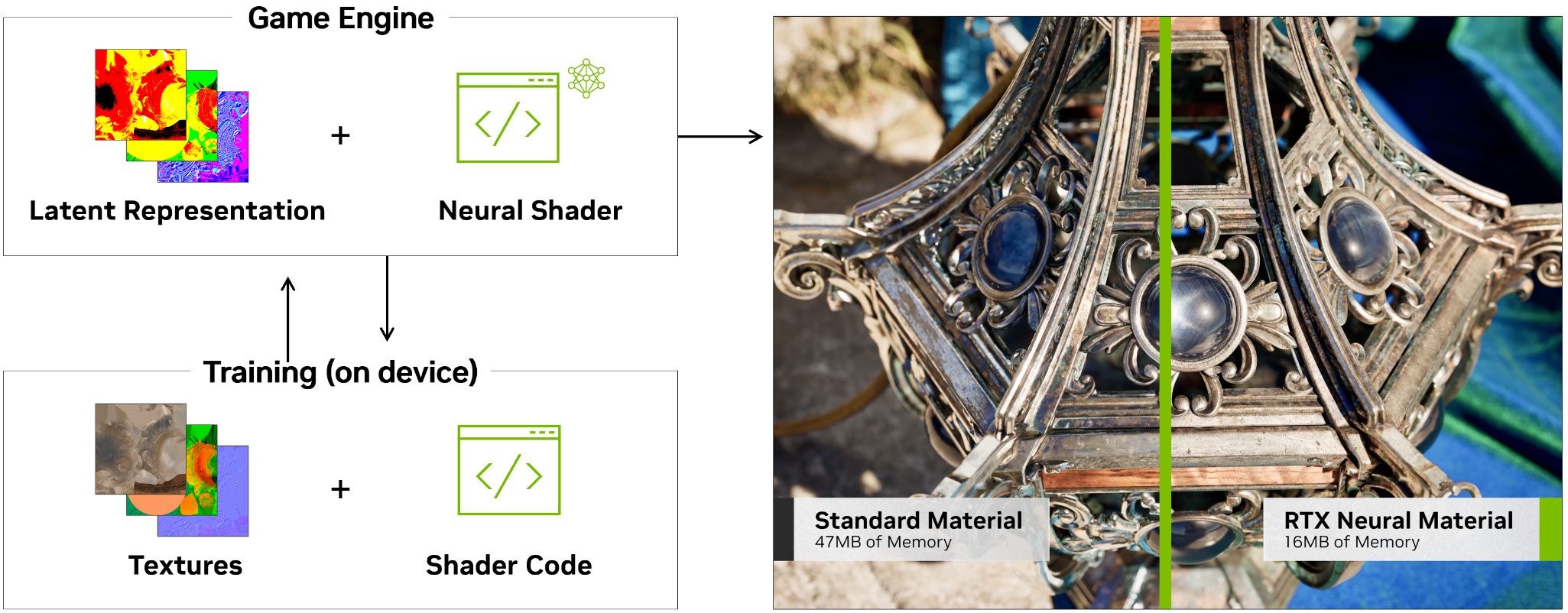
Первое направление понятно из названия – сжатие текстур. Благодаря нейросетям объем потребления VRAM можно сократить до 7 раз, сохраняя сопоставимое качество.

Второй – обработка сложных многослойных материалов, таких как фарфор или шелк. В этом направлении ожидается ускорение до 5 раз.

Третий же связан с освещением. С помощью тренировки нейросети в реальном времени создается и отправляется в кэш приблизительная модель косвенных или вторичных отражений лучей. Это значительно упрощает и ускоряет процесс трассировки, ведь RT-ядрам нужно просчитывать только первоначальные отображения.
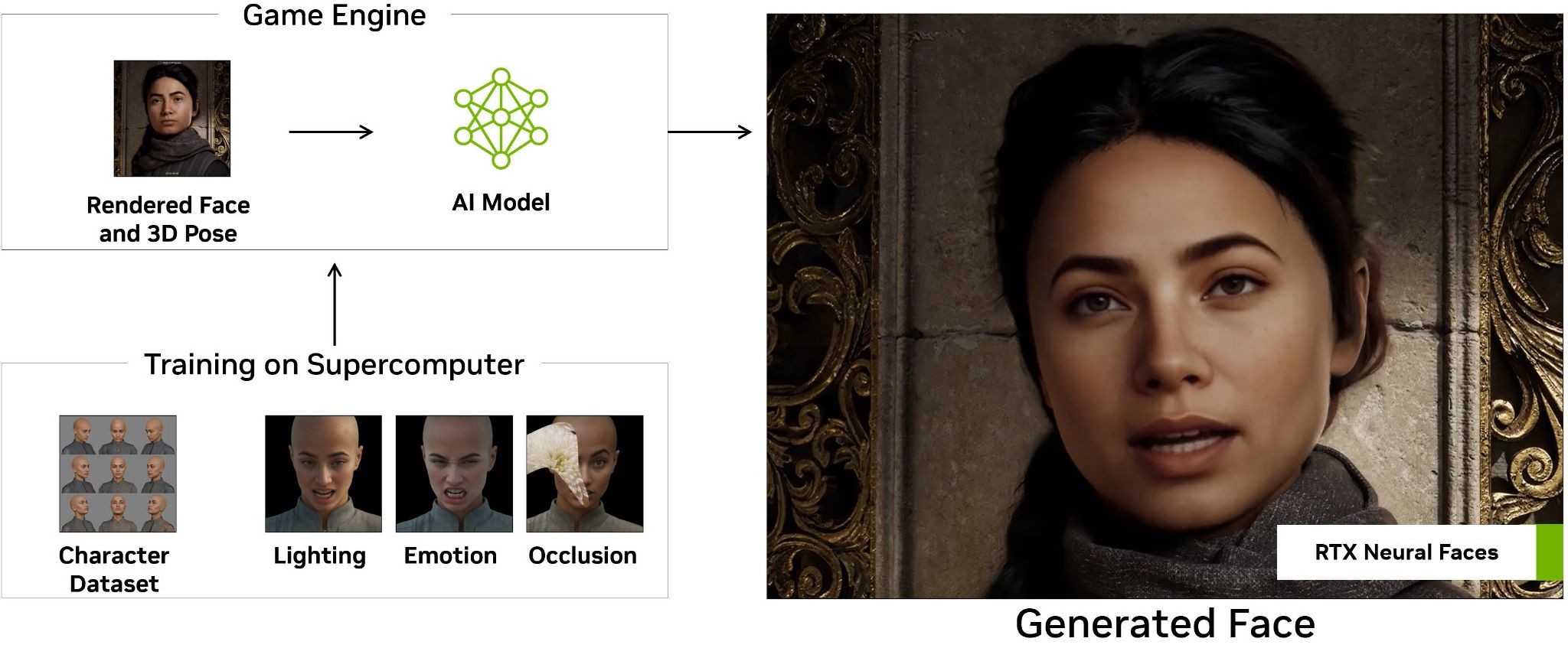
Отдельно стоит упомянуть механизм создания лиц, обычно нуждающийся в значительных ресурсах GPU. Угадайте, на чем он теперь будет прорабатываться? Верно, на нейросетях. Берется растровое изображение лица и его 3D-координаты в определенном кадре и все это миксуется и оптимизируется с множеством заранее сгенерированных вариантов освещения, эмоций, профилей или других объектов, с которыми это лицо может взаимодействовать.
Если еще не устали от теории, переходим к более прикладным вещам – непосредственно к видеокарте.

Изучать возможности линейки Blackwell начнем с предтоповой модели, которая оказалась у нас на руках – Palit GeForce RTX 5080 GameRock.

Если рассматривать чип RTX 5080 (он же GB203) и подсистему памяти, то по количеству вычислительных блоков и микросхем VRAM это, по сути, половина RTX 5090. GPU содержит 10752 CUDA-ядра, по 336 текстурных конвейеров и тензорных 1 ядер RT-ядра. Рабочая частота в базовом режиме составляет 2295 МГц, а в бустовом – до 2617 МГц. Кэш первого уровня – по 128 КБ на каждый SM, а общедоступный L2 вмещает до 64 МБ данных. Шина GDDR7-памяти 256-битная с эффективной частотой в 30 гигабит в секунду и общей пропускной способностью почти в 1 ТБ. Общий объем VRAM – 16 ГБ. Теплопакет устройства тоже впечатляет – его максимальная планка заявлена на уровне 360 Вт.


В конструктивном плане нам достался еще тот монстр. Длина видеокарты составляет около 332 мм, а толщина занимает 3,5 слота. Есть здесь и интересная подсветка, и крутые «турбовентиляторы» на двойном шарикоподшипнике. Однако с большим количеством деталей рекомендуется ознакомиться в отдельном обзоре.
Оппоненты

Сравнивать новинку будем, прежде всего, с предшественницей – Palit GeForce RTX 4080 SUPER JetStream OC.

Шейдерных вычислителей у нее чуть меньше – 9728, да и по другим характеристикам она почти не уступает – текстурным и тензорным ядерам по 304, блокам растеризации так же 112, а RT-ядерам – 76. Кэш L2 между поколениями не изменился – 64 МБ, как и шина памяти 6 и объем 6 соответственно. Однако сама память стандарта GDDR6X более медленная и способна пропускать всего около 720 ГБ в секунду. TDP карты – 320 Вт.

Далее узнаем, как героиня обзора смотрится на фоне ускоренной Palit GeForce RTX 4080 SUPER JetStream OC. Будет ли между картами какая-нибудь разница? Ведь с этой соперницей гандикап по исполнительным блокам еще меньше.

Также рассмотрим топ 40-й линейки – Palit GeForce RTX 4090 GameRock OC. Это противостояние тоже стоит внимания, ведь, например, RTX 4080 в свое время уверенно опередила не только RTX 3090, но и ее Ti-версию.

И на сладкое у нас остается ASUS TUF Gaming Radeon RX 7900 XTX OC Edition, бескомпромиссное решение из противоположного лагеря. Если не учитывать рейтрейсинг, то для RTX 4080 и ее SUPER-версии это серьезный соперник в погоне за большим FPS.
Тестовый стенд

К тестированию видеокарт нам удалось обновить тестовый стенд, чтобы он лучше отвечал максимальным требованиям современных игр.

В его основе теперь работает 8-ядерный 16-поточный игровой процессор Ryzen 7 9800X3D под сокет AM5. Рабочие частоты «новинки» варьируются от 4,7 до 5,2 ГГц, а L3-кэш достигает 96 МБ. В ближайших обзоре мы непременно доберемся и до его сравнения, следите, не пропустите!

Возвращаемся к тестовому стенду. Для нового процессора выбрали топовую и актуальную материнскую плату – ASUS ROG STRIX X870E-E GAMING WIFI.

Охлаждался процессор 360 мм СЖО ASUS TUF Gaming LC II 360 ARGB.

Для хранения временных данных использовали двухмодульный комплект Kingston FURY Renegade RGB DDR5-6400 объемом 32 ГБ с таймингами 32-39-39 и напряжением 1,4 В. Выглядит ОЗУ стильно, а 12-точечная RGB-подсветка придает еще большей эффектности.

Операционную систему и вспомогательный софт хранили на оптимальном по соотношению цена/возможности M.2 PCI-E 4.0 x4 накопителе Kingston KC3000 на 1 ТБ. Он обеспечивает до 7000 МБ/с при считывании и 6000 МБ/с при записи, а производительность на случайных 4K-блоках составляет 1 миллион IOPS. Подобрать оперативную память или SSD-накопитель Kingston можно на сайте kingston.com, где удобный инструмент для подбора оперативной памяти – достаточно ввести название материнской платы или ноутбука, и система подберет совместимые комплектующие.

Обеспечивал питание киловаттный Seasonic VERTEX GX-1000 с сертификатом 80 Plus Gold, гарантирующий высокую энергоэффективность.

И в единую цельную конструкцию все комплектующие собрал корпус ASUS TUF Gaming GT302 ARGB, который оснащается четырьмя дополнительными вентиляторами.
Прогрев
Новая видеокарта, впечатляющий TDP. Интересно, как она охлаждается и насколько эффективно?
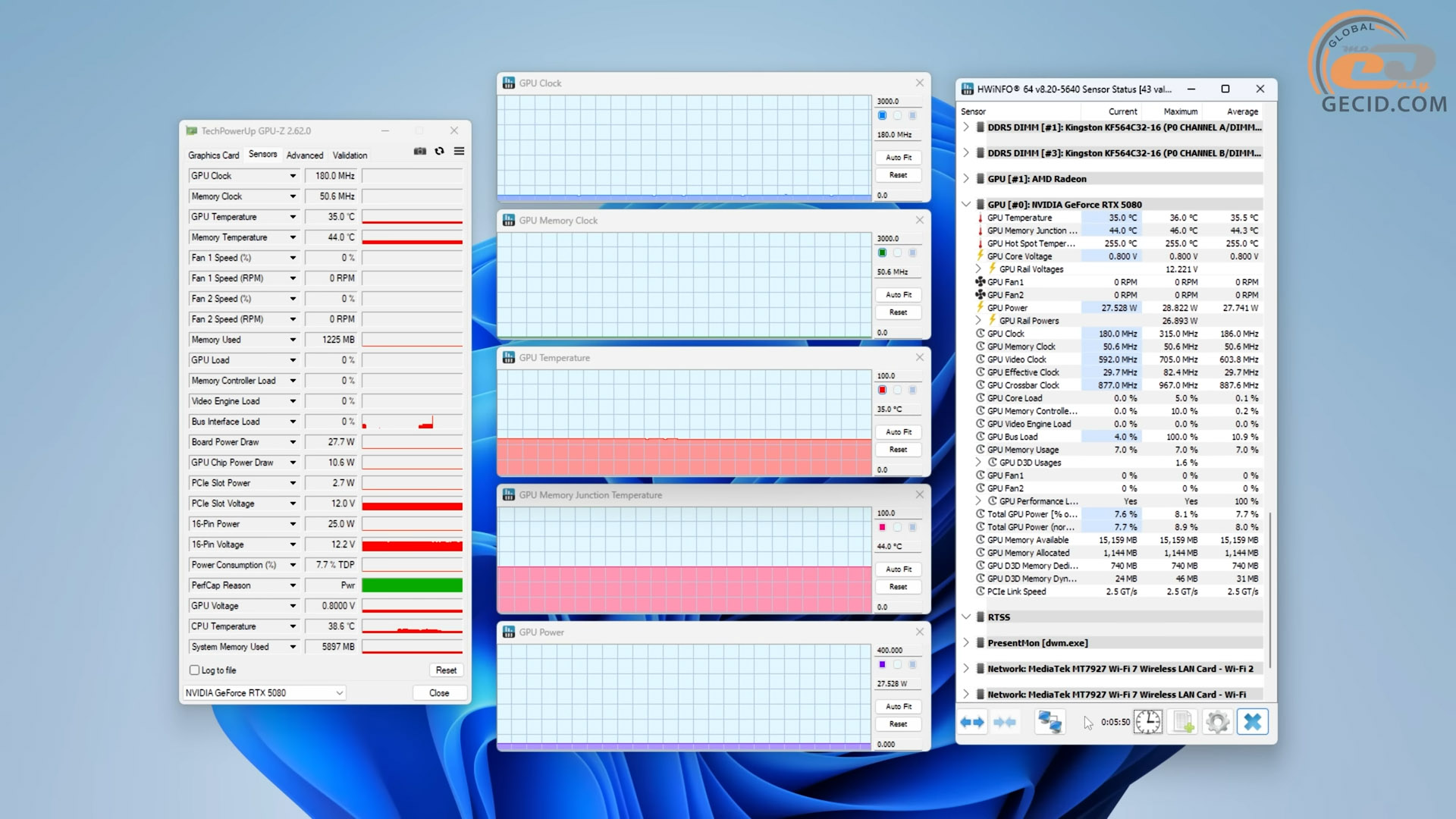
Без 3D-нагрузки температура GPU в пассивном режиме вентиляторов составила скромные 35 градусов. Потребление не превышало 30 Вт. Ничего удивительного.
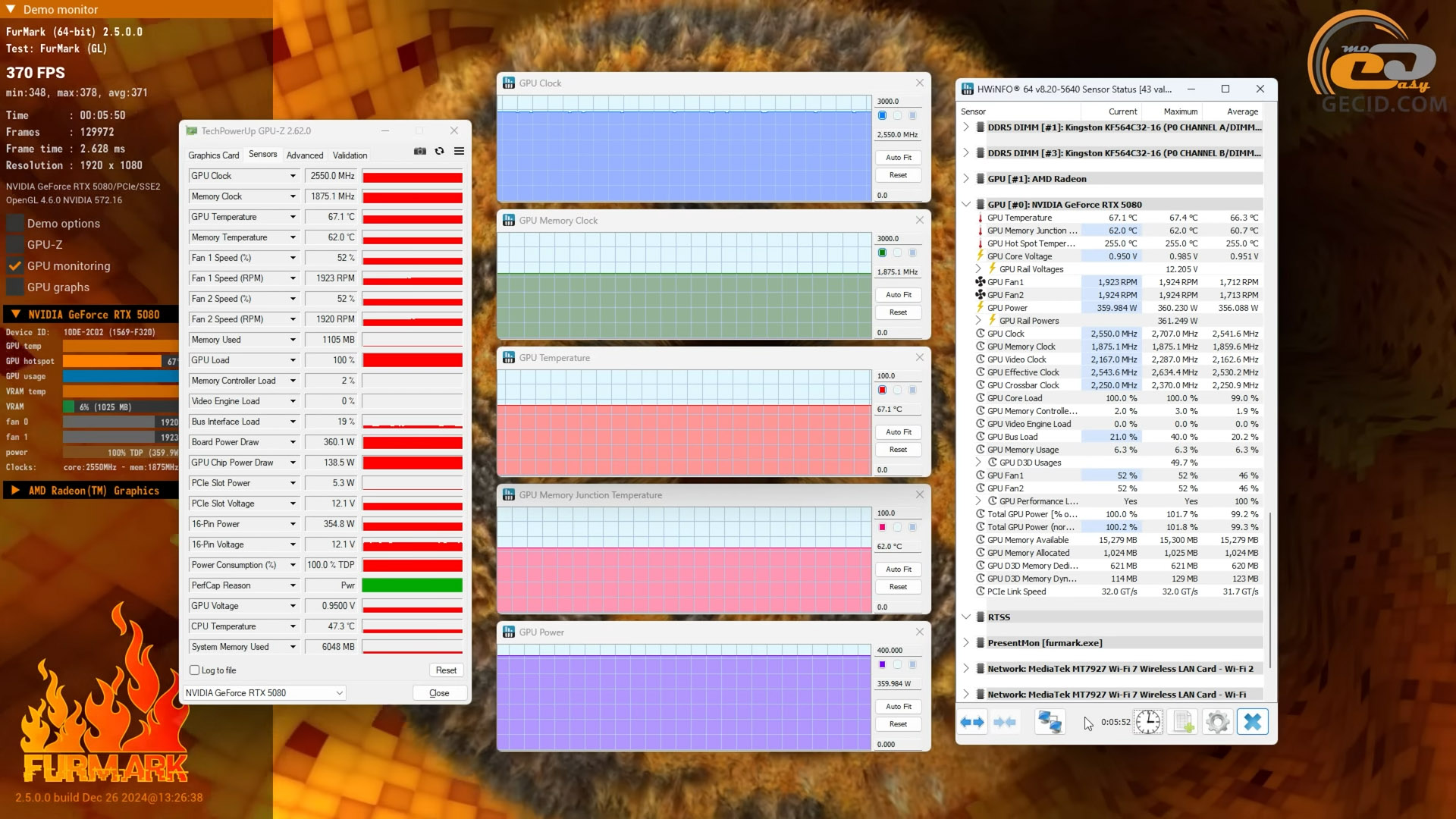
Под стрессом в FurMark, как ни странно, тоже все хорошо – 67 градусов на чипе, 62 на VRAM, и это при реальных 360 ваттах потребления. Массивная система охлаждения работает безупречно.
Синтетика
Прежде чем переходить к синтетическим тестам, одно уточнение. Поскольку RTX 5080, мягко говоря, продукт новый, у бенчмарков возникли некоторые проблемы. К примеру, Cinebench 2024 вообще не смог распознать видеокарту.
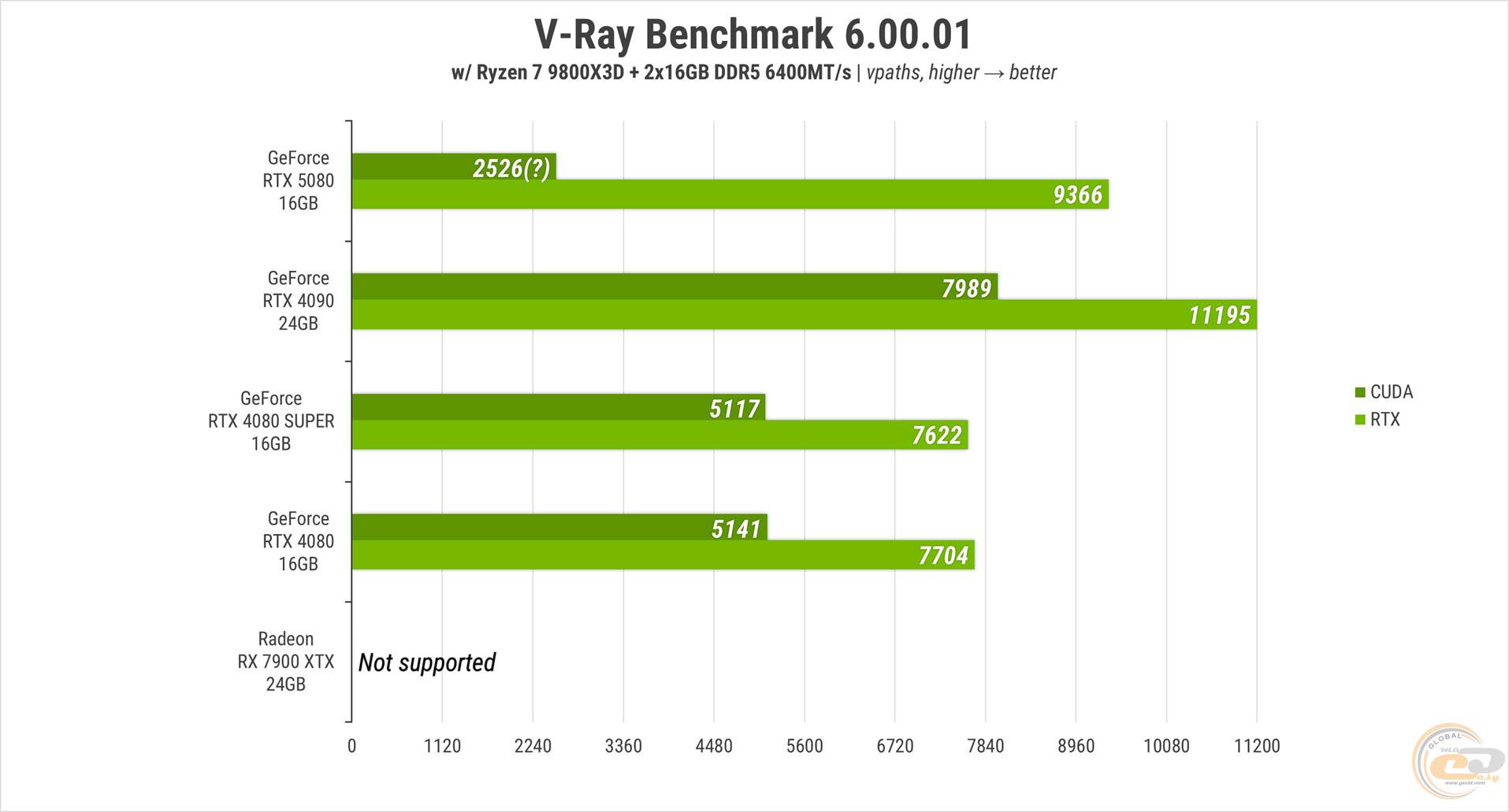
V-Ray Benchmark неплохо оценил производительность RT-ядер у испытуемой карты, но не смог нормально скачать шейдерные вычислители. Потому и результат такой аномально низкий.
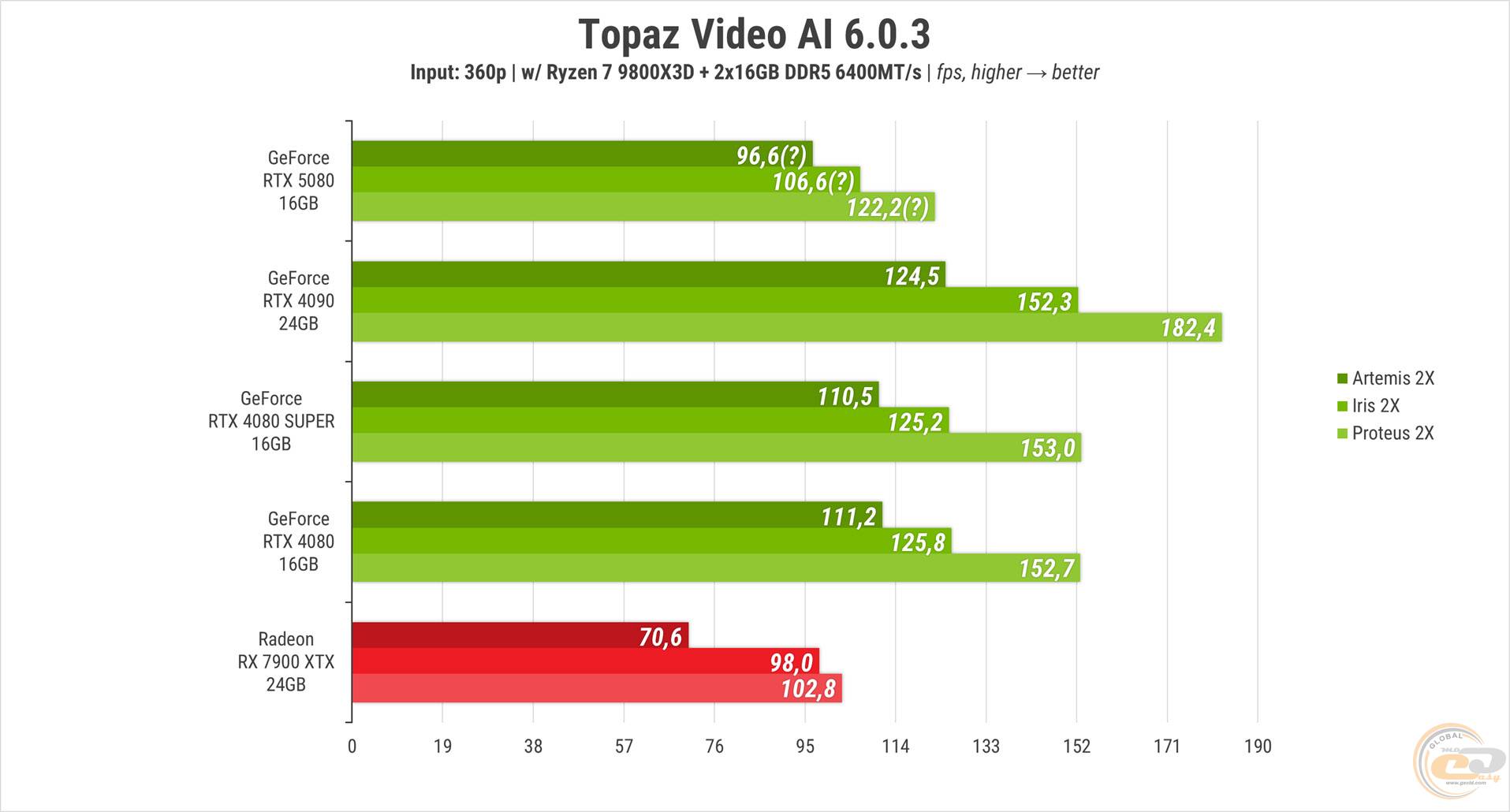
К этому хаосу приобщился и Topaz Video AI, продемонстрировав подозрительно низкую производительность новинки.
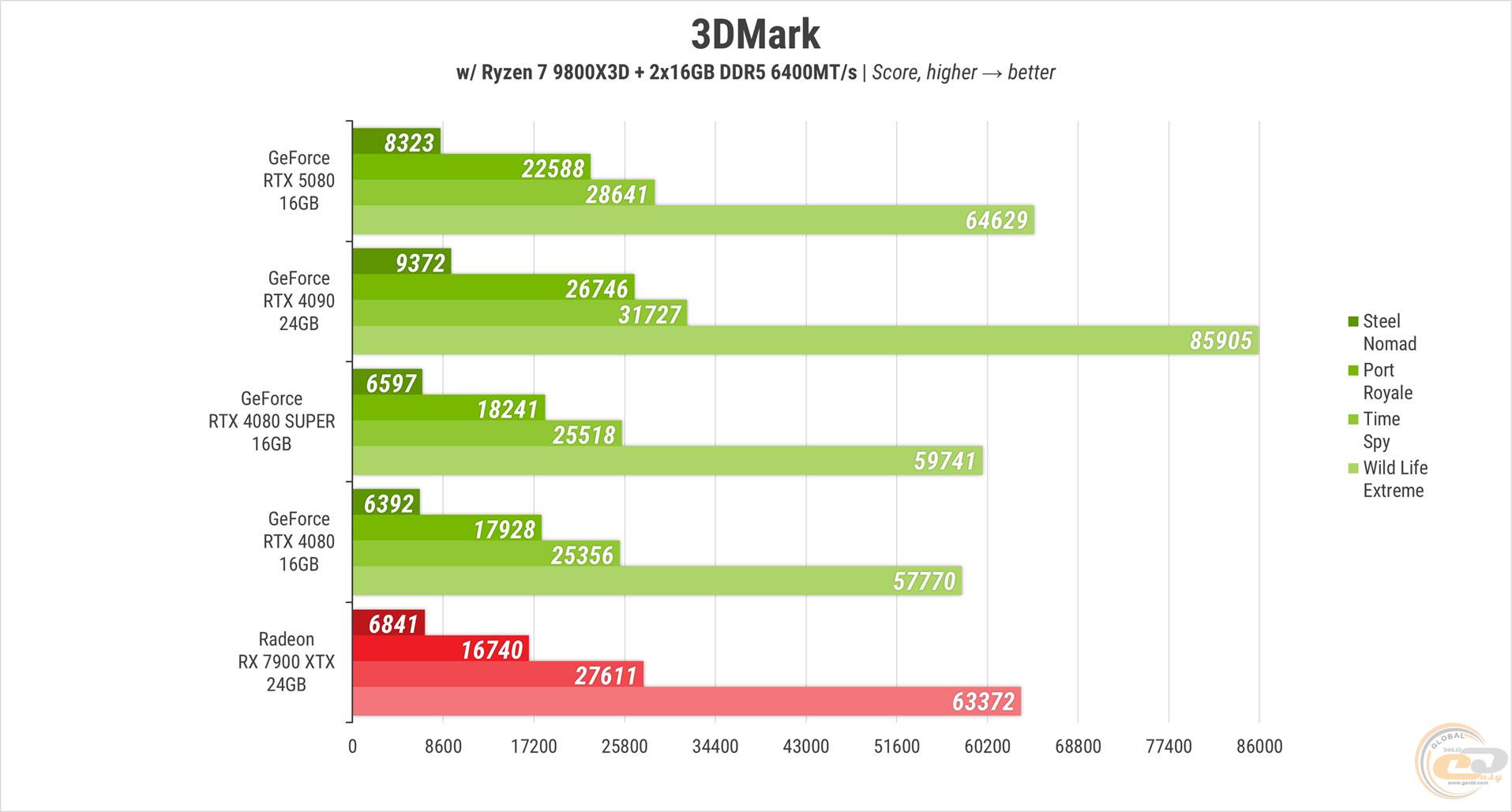
В 3DMark «попугайчики» выглядели уже более или менее опрятно, ярко и логично. Героиня обзора опережает RTX 4080 на величину до 30%, ее SUPER-версию – до 26%, а RX 7900 XTX – до 35%. В то же время уже не-топу NVIDIA она серьезно проигрывает - до 25%.
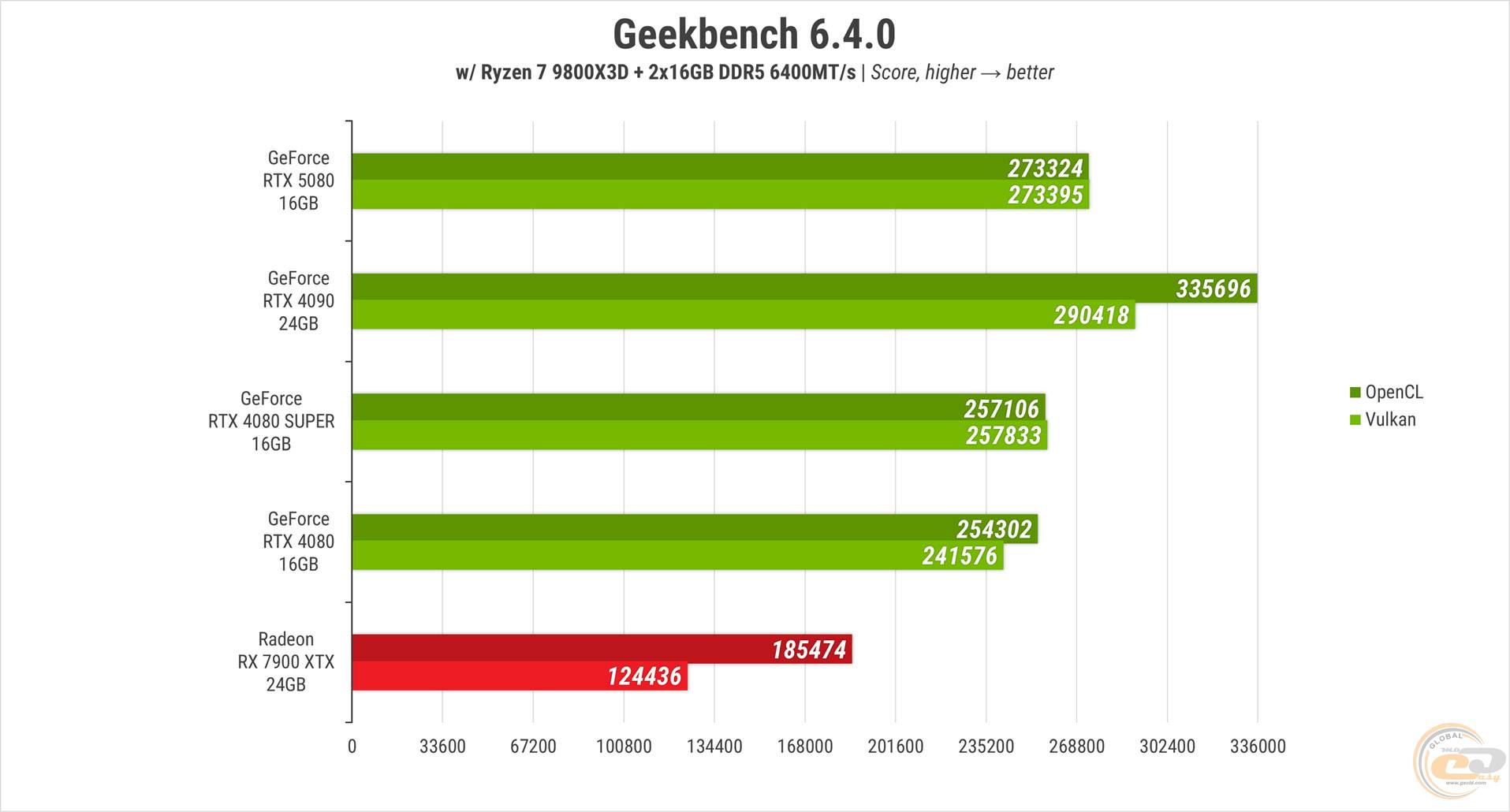
Geekbench 6, похоже, сумел правильно оценить способности видеокарты. Свою предшественницу RTX 5080 опережает на 7-13% в зависимости от API, на 6% обходит RTX 4080 SUPER и значительно опережает RX 7900 XTX – на 48-120%. Быстродействие RTX 4090 остается недостижимым, он демонстрирует на 6-23% лучшие результаты.
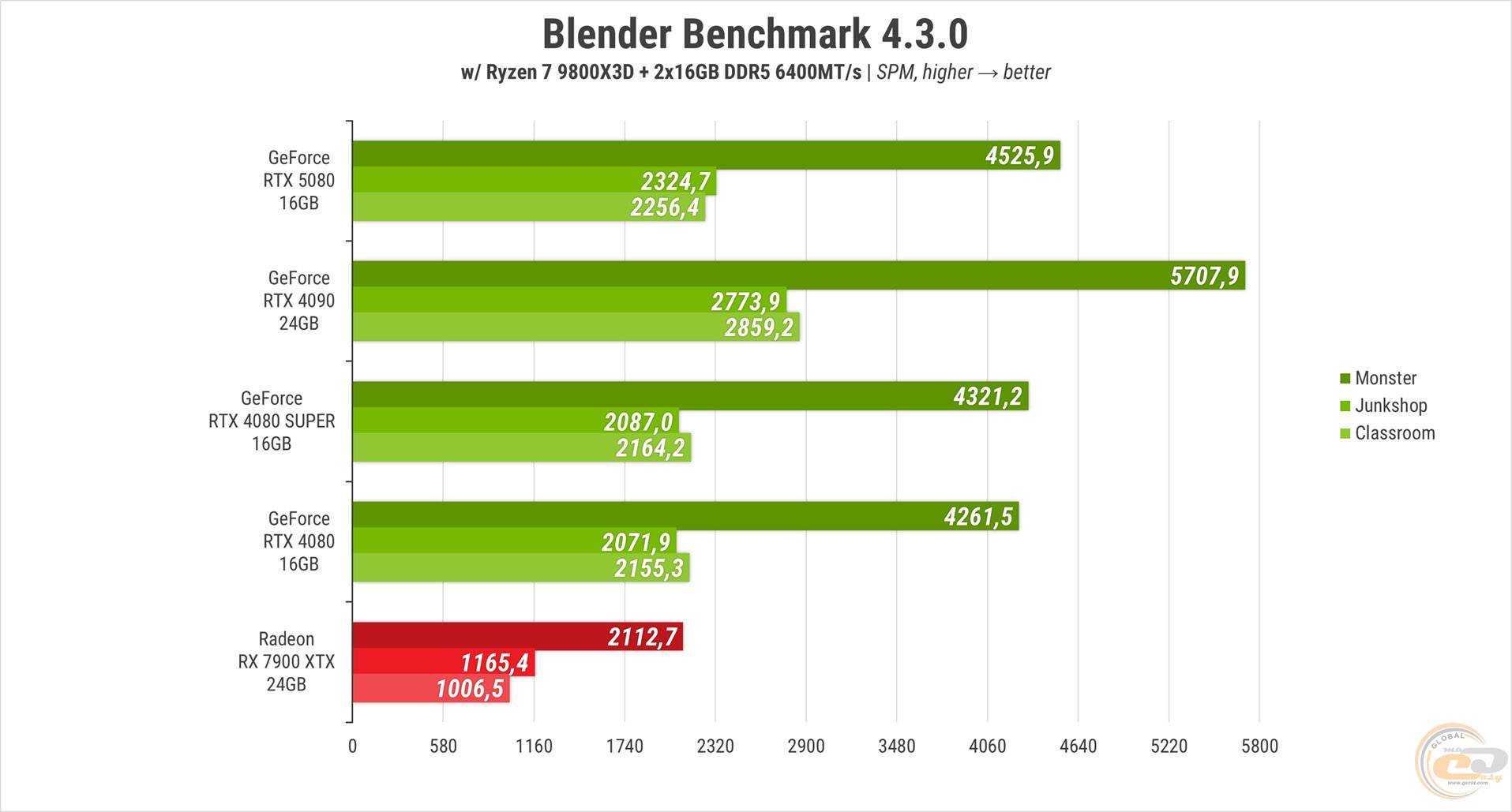
В Blender героиня обзора опередила обе предыдущие 80-ки примерно на 12%. Но снова уступила топу зеленых из прошлого – на 16-21%. Карта красных в данном соревновании не конкурент, ее результаты вдвое меньше конкурентов.
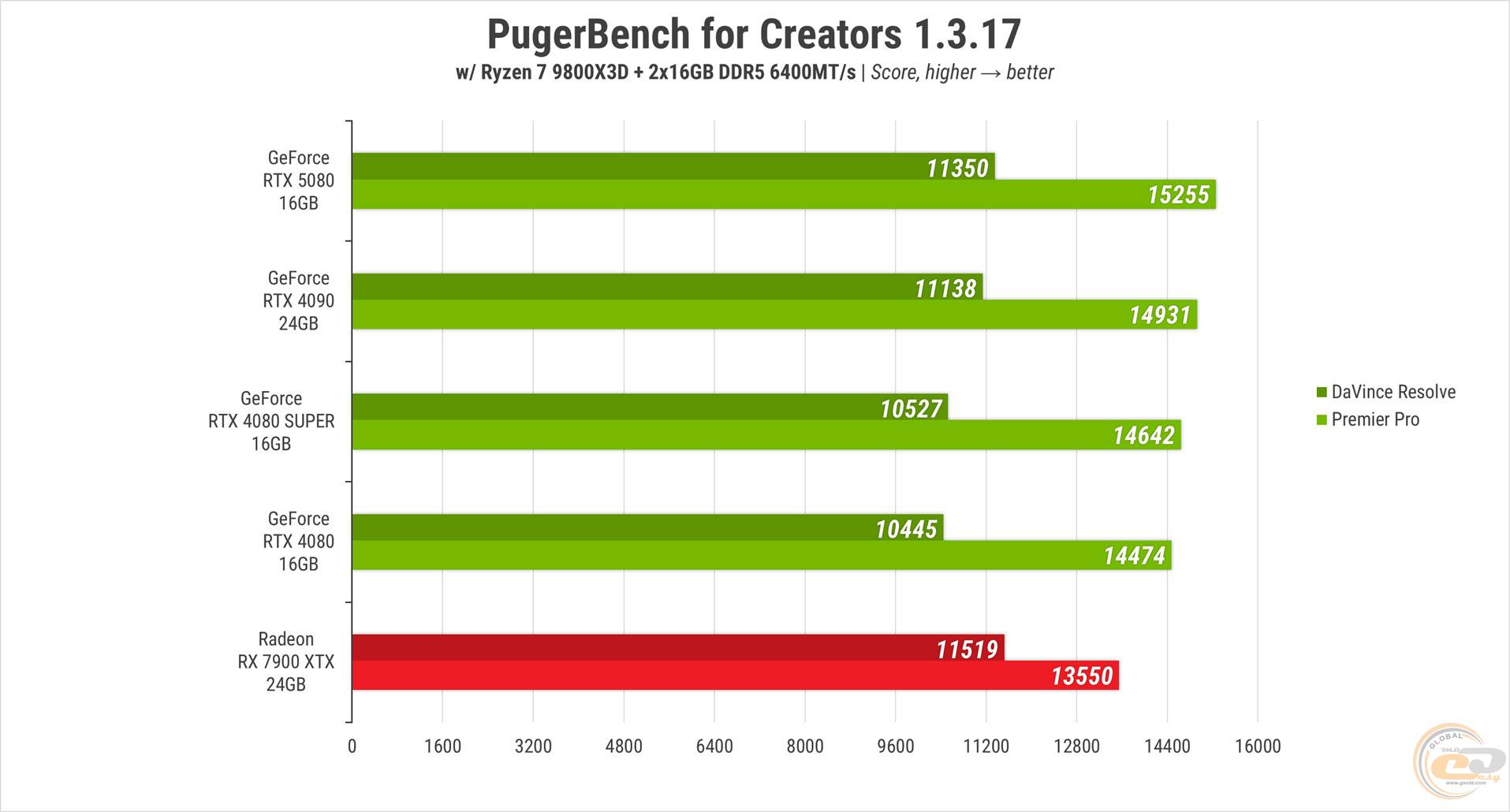
Бенчмарк профессиональной нагрузки, Puget Bench for Creators, присудил RTX 5080 самую высокую позицию среди карт NVIDIA. RTX 4090 отстала на несколько процентов, а обе RTX 4080 позади на 4-8%. Ускоритель красных в данном случае – темная лошадка, ведь в одном из тестов даже показал лучший результат.
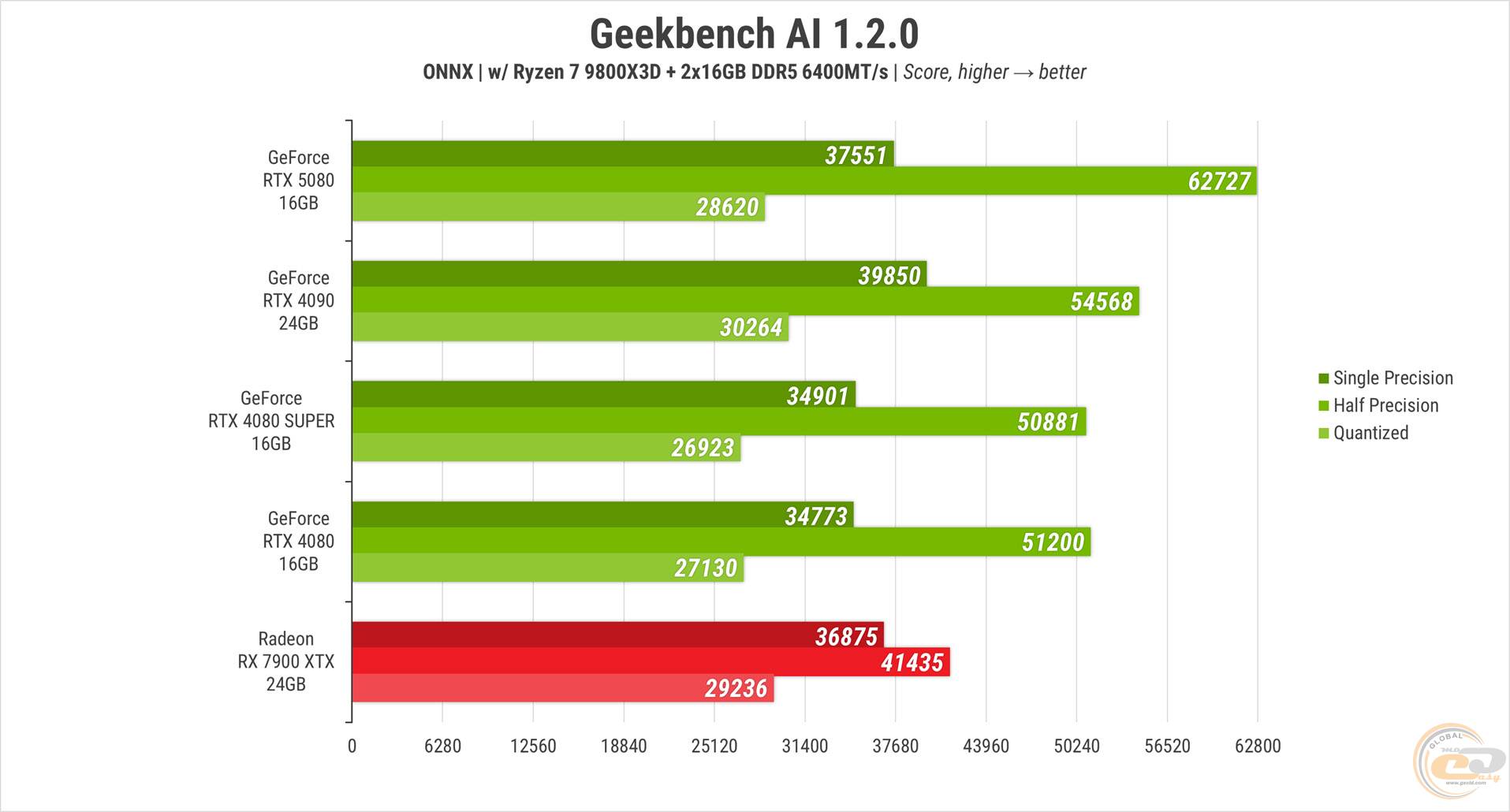
Также довольно уверенно RTX 5080 показала себя в Geekbench AI. И хотя RTX 4090 опередила ее у двух из трех типов расчетов с преимуществом в 6%, в режиме с половиной точностью вычислений новинка оказалась на 15% быстрее. Остальные карты 40-й серии, как и RX 7900 XTX, значительно отстали.
Игры
Теперь переходим к играм, которые тестировались исключительно в 4K, ведь именно на это разрешение ориентирована героиня обзора. Апскейлеры и фрейм-генерацию не использовали, чтобы оценить прирост чистой производительности нового поколения.
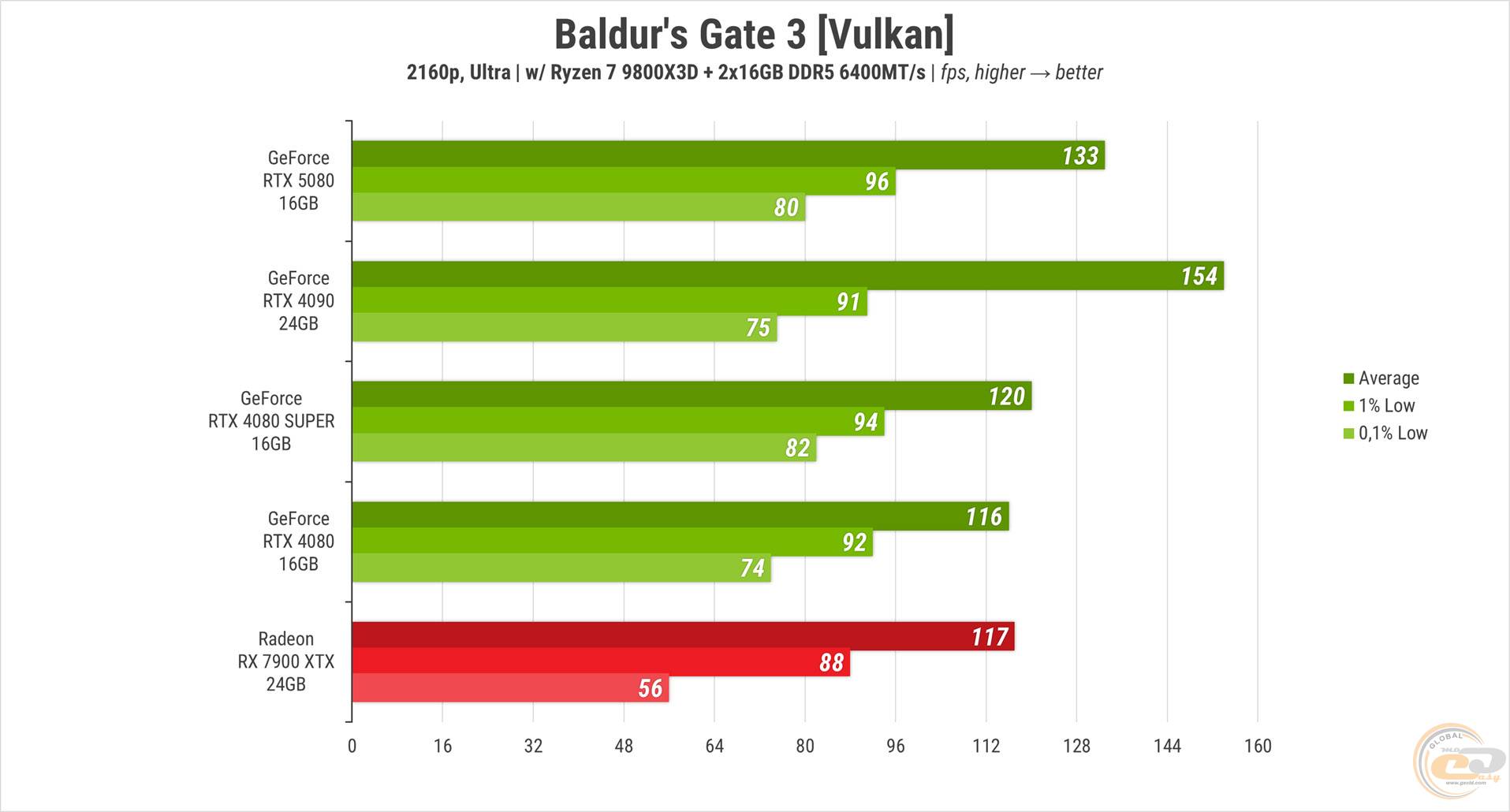
Пробежка в Baldur's Gate 3 проводилась на «ультре» пресете в третьем акте. И первая же игра показала, что сравнивать RTX 5080 с RTX 4090 по сырой производительности, вероятно, не стоит. Старушка оказалась быстрее почти на 16% по средней частоте кадров, хотя минимальный FPS у нее был несколько ниже. Отрыв новинки от обоих 80-к также не выглядит значительным – 11% от SUPER-версии и почти 15% от обычной. Результат красной карты почти на уровне RTX 4080 SUPER.
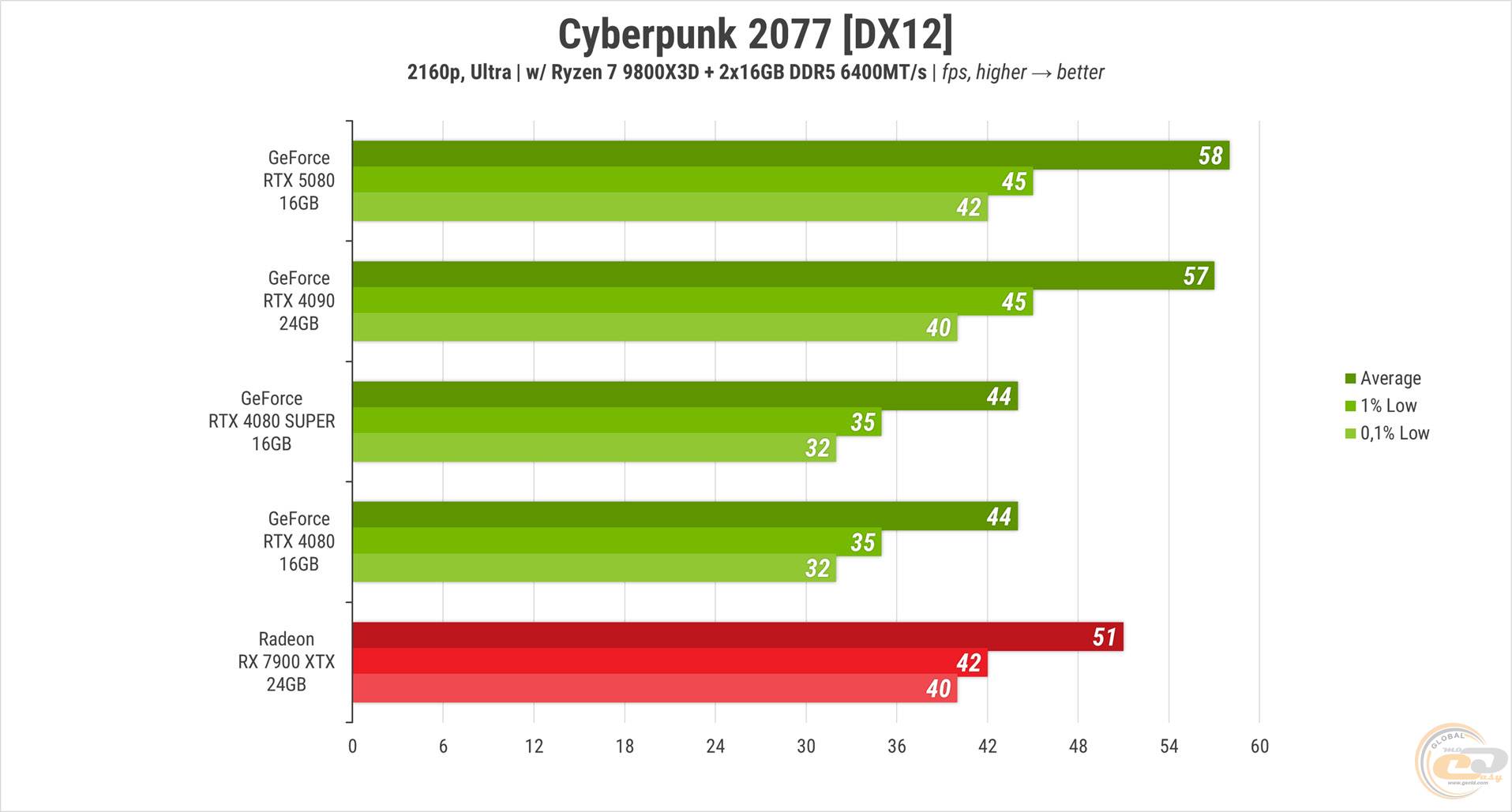
Луч надежды озарил наши лица в Cyberpunk 2077 на максимальных настройках без RT. RTX 5080 неожиданно сравнялась с RTX 4090, даже опередив ее на 1 FPS в среднем. Поначалу показалось, что упираемся в производительность процессора, но мониторинг и результаты других карт развеяли это предположение. RX 7900 XTX оказалась позади на 12%, а обе RTX 4080 – на 24%.
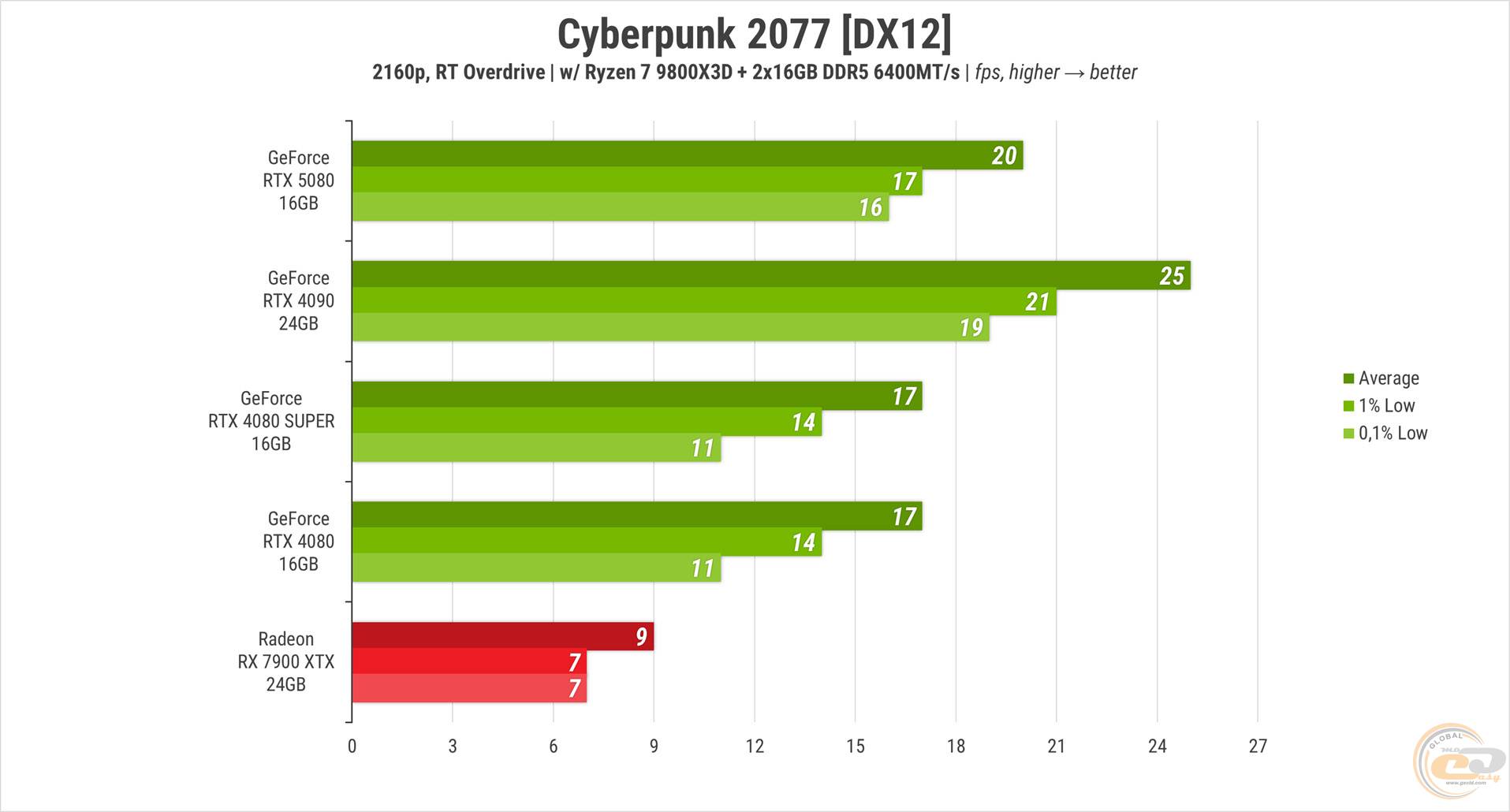
Включаем «овердрайв», то есть трассировку пути, и получаем почти слайд-шоу на всех видеокартах NVIDIA, а на RX 7900 XTX –именно его. Лидером остается RTX 4090 с на четверть высшим средним счетчиком.
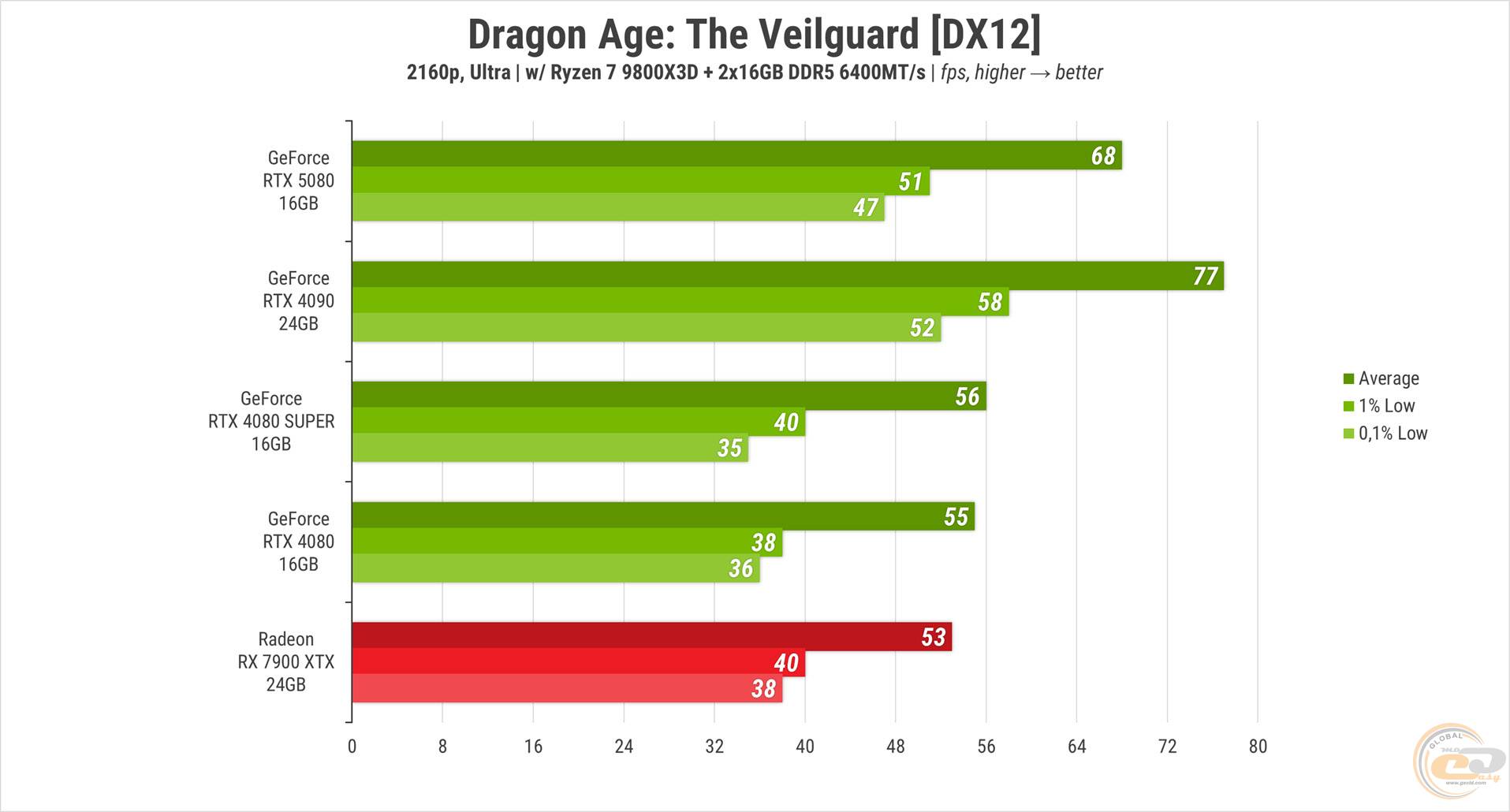
В Dragon Age: The Veilguard с «ультрами» настройками RTX 5080 оказалась между топом 40-й линейки и всеми другими участницами, показавшими почти одинаковый FPS и не смогли преодолеть границу в 60 кадров. Новинка же превзошла этот показатель на 8 FPS. Следует отметить, что игра частично использует трассировку лучей на этом пресете.
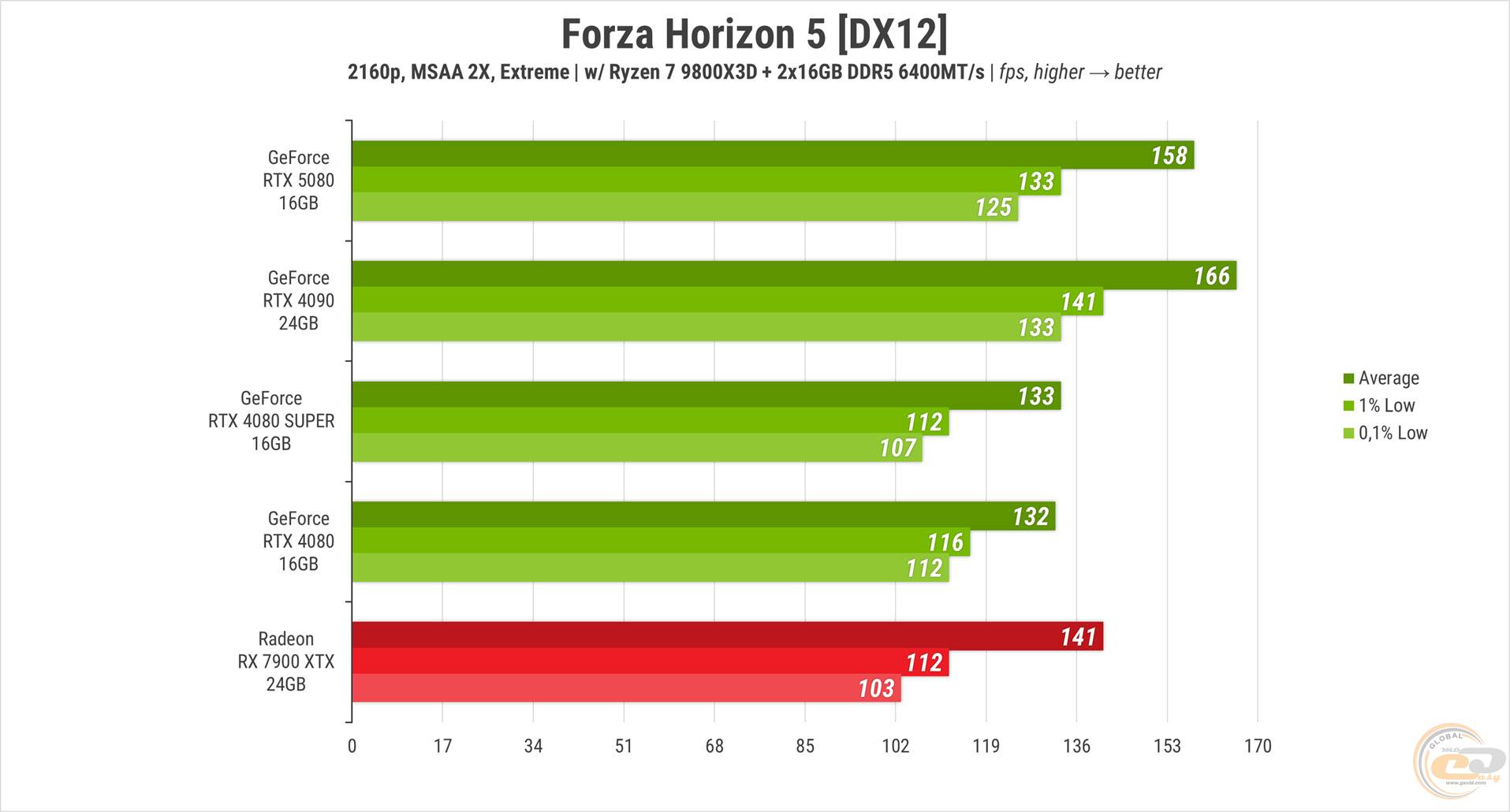
В Forza Horizon 5 подопытной карте не хватило всего 5% среднего FPS, чтобы догнать RTX 4090. В то же время она уверенно опередила RTX 4080 и ее SUPER-версию на 20 и 19% соответственно. Красной участнице удалось ближе всего подобраться к новинке, отстав на 11%.
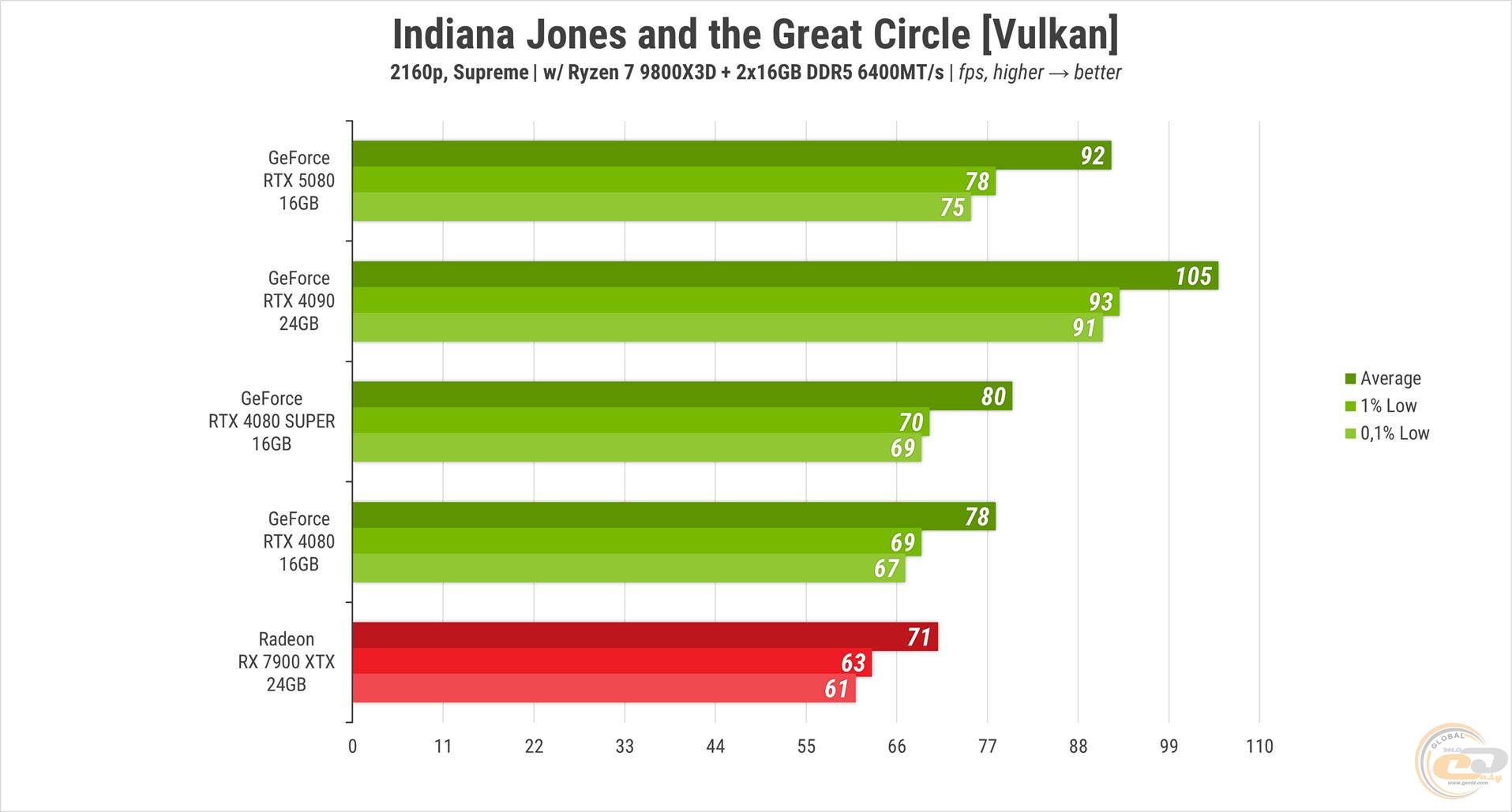
Indiana Jones and the Great Circle с пресетом «Supreme» лишь закрепила тенденцию: RTX 5080 опережает предыдущие 80 примерно на столько же, на сколько отстает от топовой модели. Своеобразный «золотой середняк». RX 7900 XTX в этом сравнении оказалась еще на ступеньку ниже обеих RTX 4080.
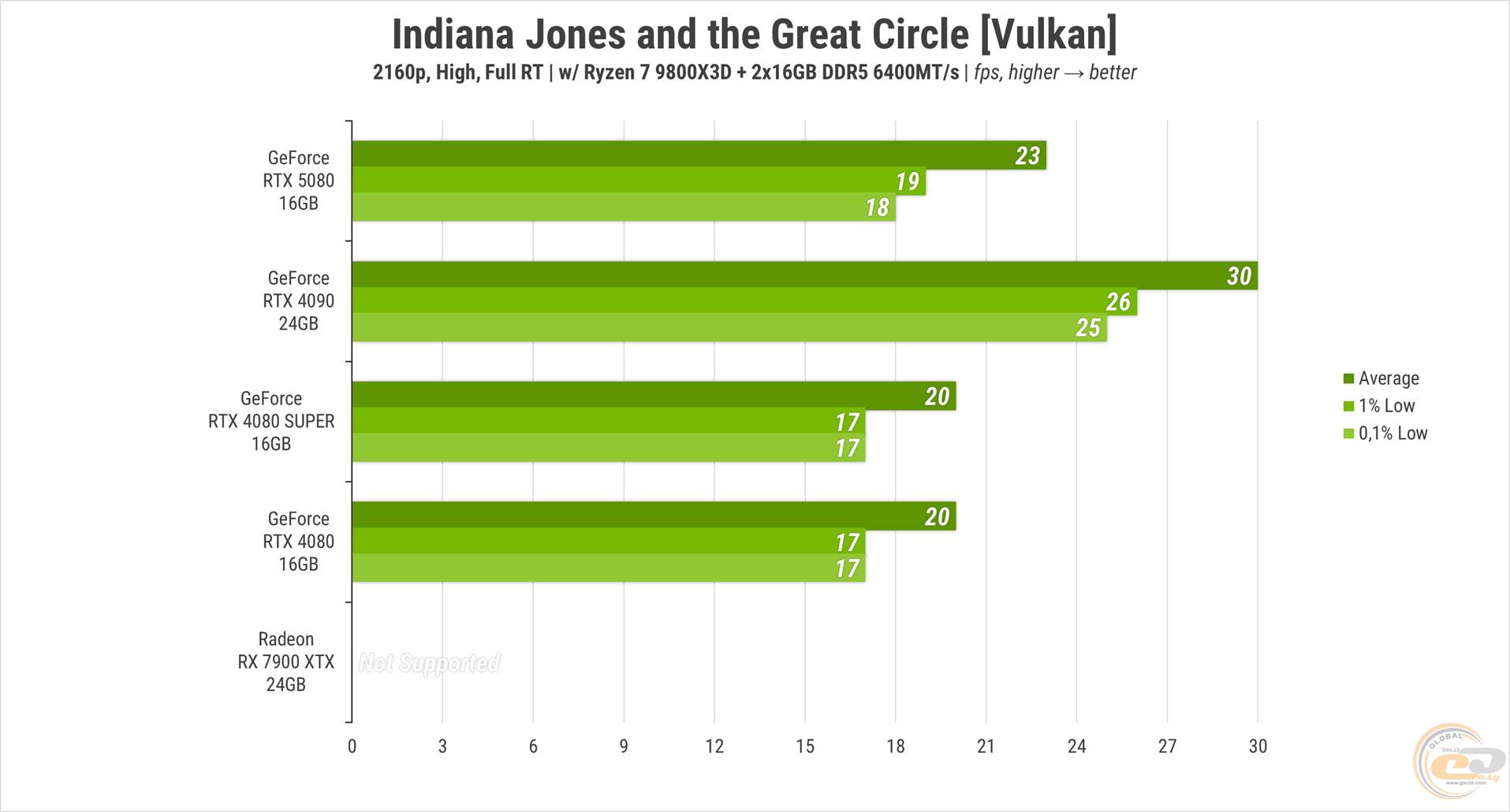
С включенной полной трассировкой лучей игра становится неподъемной для всех видеокарт, даже на более скромном «высоком» пресете. Если только вы не поклонник консольных 30 FPS — но даже их смогла потянуть только RTX 4090. Красный ускоритель вообще остается за бортом, поскольку игра не предполагает поддержки RT для него.
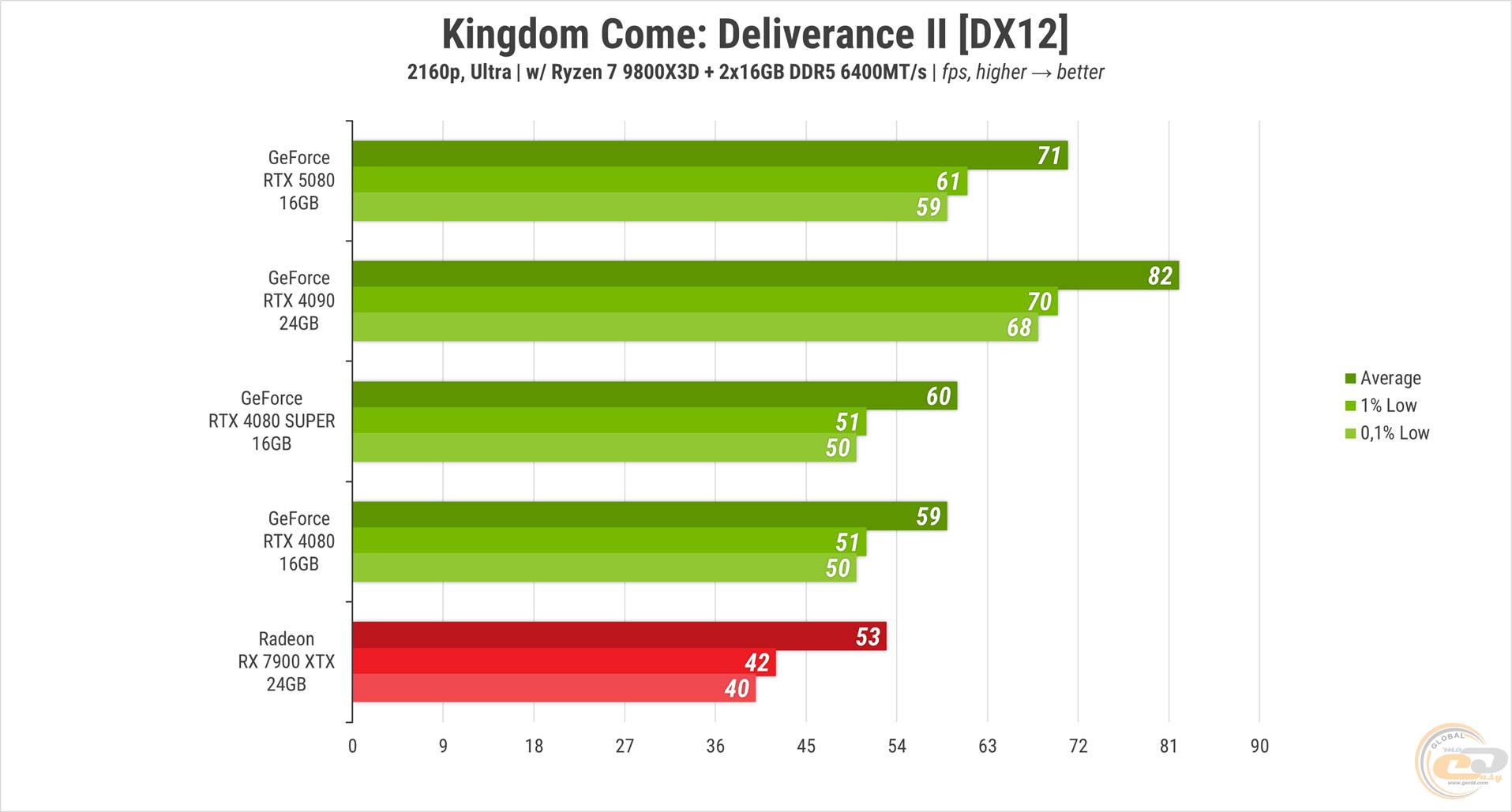
С KingdomCome: Deliverance II на «ультрах», в сущности, все тоже самое. RTX 5080 обновляет изображение на 18-20% быстрее чем обе предшественницы, но на почти 16% медленнее RTX 4090. RX 7900 XTX снова позади – ее средний FPS на 25% ниже, и это единственная карта в тесте, которая не смогла обеспечить стабильные 60 кадров в секунду.
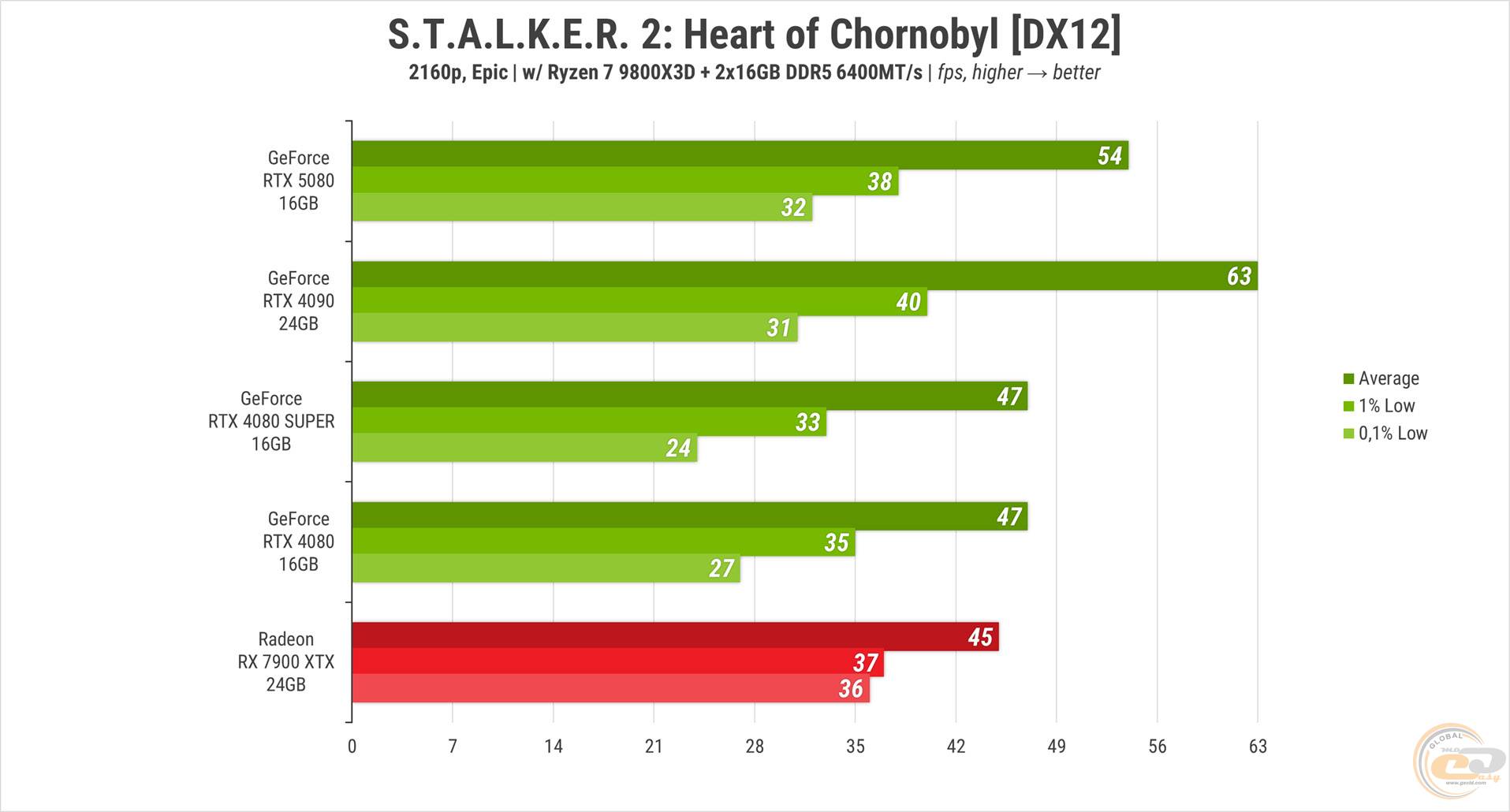
Во втором "Сталкере" на "эпических" настройках заметно сильное проседание показателя 0.1% Low у RTX 4080 и 4080 SUPER по сравнению с другими участницами теста. В остальном же ситуация ожидаемая: RTX 5080 опережает обе 80-ки на 15%, а ее на почти 17% опережает RTX 4090. RX 7900 XTX в очередной раз на последнем месте, отставая от новинки на 17% по средней частоте кадров.
DLSS 4
Далее решили проверить, как на практике работает DLSS четвертой ревизии, и прежде всего оценить, привело ли к улучшению изменение модели CNN на Transformer качества изображения при апскейлинге.

Для этого запустили Cyberpunk 2077, выбрали соответствующую модель и перевели масштабирование в производительный режим. И здесь… даже не знаем, что сказать. Вроде бы и есть определенные улучшения то здесь, то там, но в 4К и при динамическом геймплее разница почти незаметна. Так что, наверное, нужно смотреть на более статические или специфические сценарии и при меньшем разрешении, что и попробуем сделаем в одном из следующих обзоров.
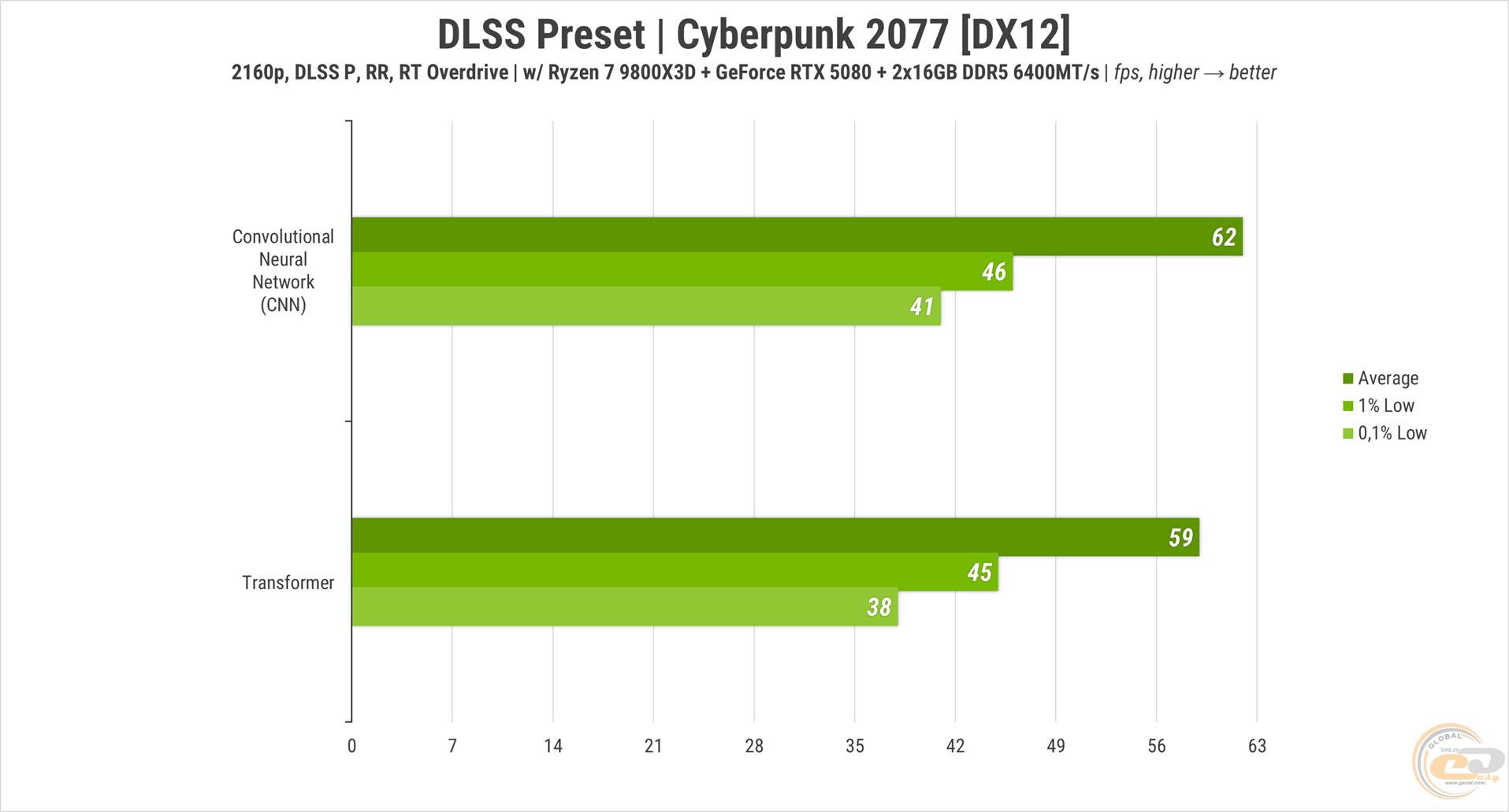
Но вот что можем подтвердить прямо сейчас – производительность с новым подходом к анализу изображения снизилась на 5%.
Продолжаем тестирование и посмотрим на мульти-фрейм-генерацию.

Первый сценарий – тот самый Cyberpunk 2077 с «продуктивно-трансформированным» DLSS, Ray Reconstruction и RT Overdrive. Без генератора кадров на RTX 5080 игра выдавала в среднем около 60 FPS. Каждый последующий множитель искусственно сгенерированных кадров повышал частоту примерно на 70-75% от базового значения. В итоге при x4 средний счетчик достиг невероятных 180 FPS с хвостиком, но без нюансов не обошлось.
Во-первых, инпут-лаг, особенно при генерации x4. С «продуктивным» апскейлером он вообще не ощущался. На «сбалансированном» уровне почти незаметен, а на «качественном» уже ощутим, но не критично. Худший опыт в этом плане дает DLAA - с таким сглаживанием задержку в управлении не заметить трудно.
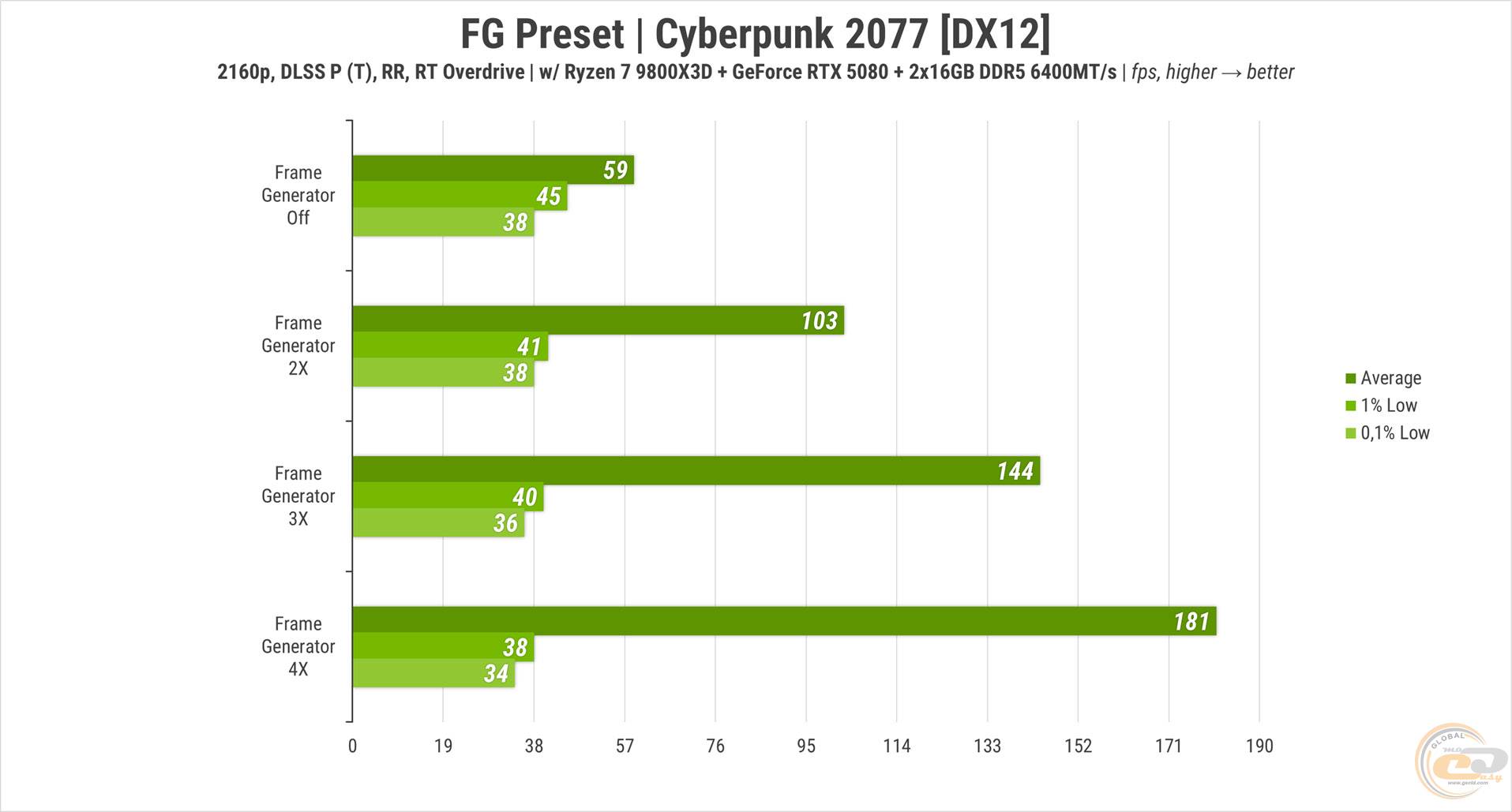
Во-вторых, показатели 0,1 и 1% Low в данном случае отражают не реальную статистику, а показывают ее для базовой частоты. И, что интересно, чем выше множитель фрейм-генерации, тем меньше на несколько кадров становится базовая частота.
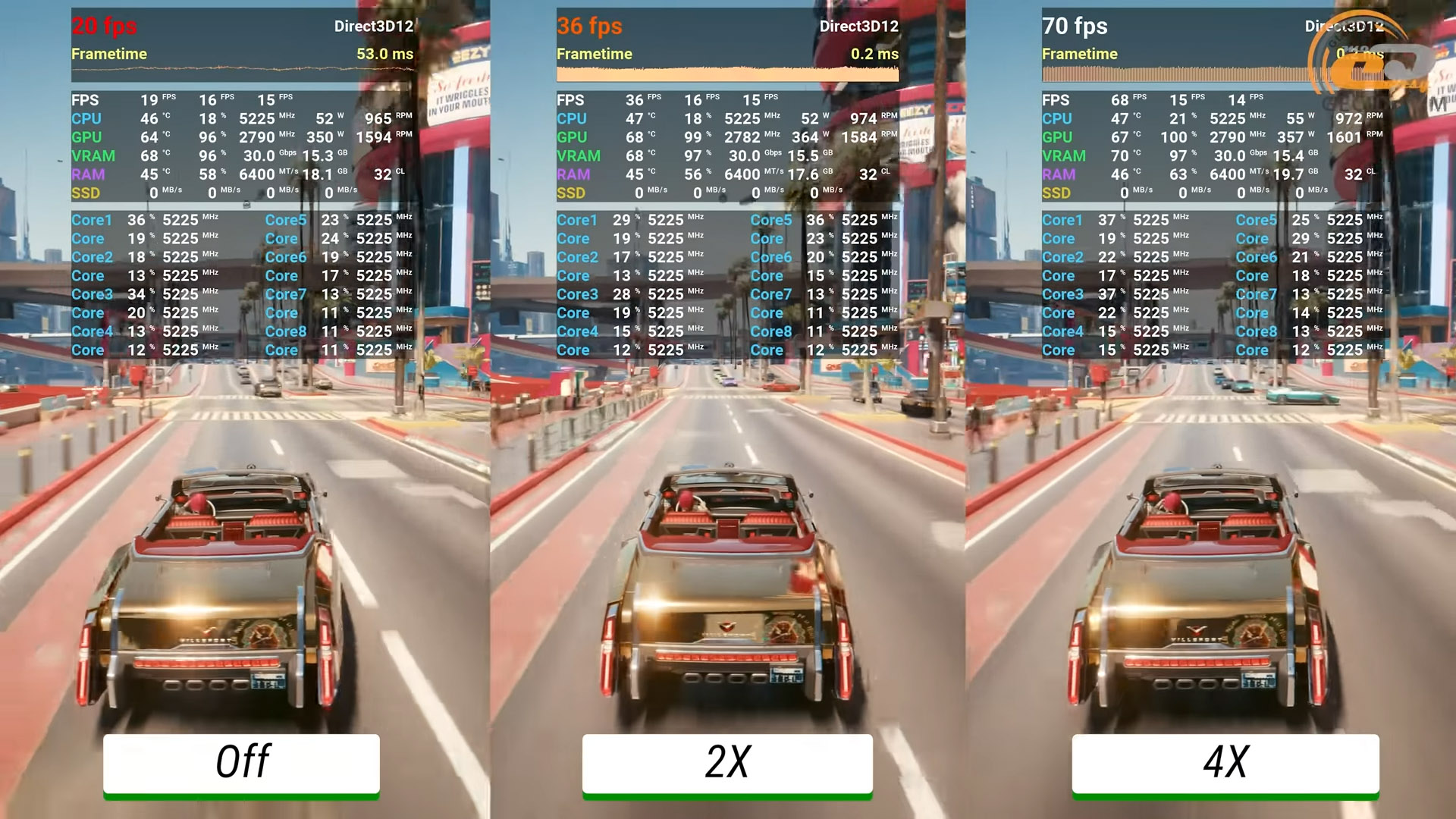
Еще один тест демонстрирует, как работает генерация кадров, когда базовой частоты обновления дисплея недостаточно. Переводим апскейлер в режим DLAA-сглаживания и наблюдаем 19 FPS в среднем без FG именно то, что нужно. Далее включаем режимы x2 и x4, что дает уже 36 и 69 FPS соответственно.
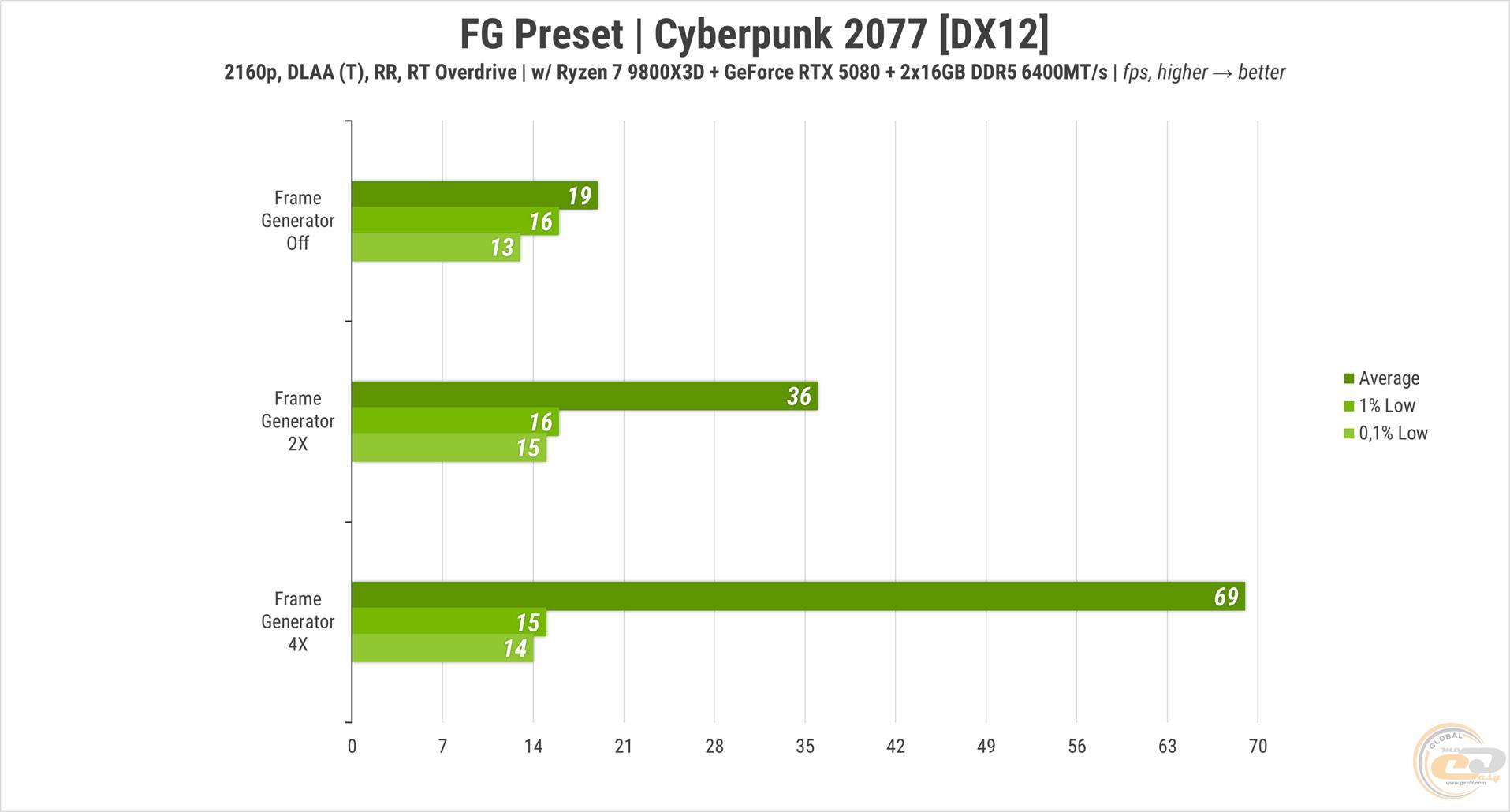
Но обратите внимание на артефакты – они почти повсюду. Хотя если просто играть и не всматриваться, сначала можно ничего не заметить.
Итоги
Итак, если оценивать GeForce RTX 5080 сугубо по производительности, создается впечатление, что перед нами не полноценное новое поколение, а просто ускоренная версия предыдущей серии. Уж слишком мало драйва она привнесла как в играх, так и рабочих приложениях.
Превосходство более 20% над аналогами прошлого поколения – редкость, а именно такие случаи можно считать успехом. Более или менее неплохо новинка выглядела только на фоне топового решения от красных, но и здесь хотелось бы большего, особенно ввиду цены. На старте продаж стоимость переваливает за 70 000 гривен, что существенно отличается от рекомендованных 999 долларов.
Но есть и положительные моменты. Мультигенератор действительно работает как заявлено и при базовой частоте обновления около 60 FPS становится полезным инструментом для высокогерцовых мониторов. Плюс многое изменилось в архитектурном плане, хотя и похоже, что работы по внедрению новых методов еще много. Мы непременно в ближайших обзорах попробуем углубиться в новые технологии более детально, так что не пропустите!

Что же касается Palit GeForce RTX 5080 GameRock, то она не просто понравилась – она удивила. Потребляя 360 Вт, карта удерживала при стрессовом нагрузке всего 67 градусов на GPU и 62 на VRAM – это просто отличный результат. К тому же и дискомфортный шум она не создавала. Да, за это придется расплачиваться большими габаритами, но времена сейчас такие и улучшений в этом направление пока не видно.
Автор: Алексей Ерин
Опубликовано : 02-06-2025
| Подписаться на наши каналы | |||||

|

|

|

|
||








